
The Self-Organization of the
European Information Society:
The case of "biotechnology"
Loet Leydesdorffand
Gaston Heimeriks
University of Amsterdam, The Netherlands
(revised version; January 1999)
Abstract
1. Introduction
In a consortium of academic research centers, a European project brings together sociological and computer science expertise under the heading of "The Self-Organization of the European Information Society."[Note 1] The common root of these two intellectual traditions is the "radically constructivist" assumption of self-organization theories: sociological reconstructions can be informed from the engineering perspective of the computer sciences. This recombination of qualitative specification with quantitative modeling is expected to stimulate the development of new methodologies to understand the complex social processes that characterize the development of the information society and its relation to the formation of a European identity.
The theory of self-organization or autopoiesis, for example, applies when the reconstructing layer and the reconstructed layer operate selectively upon each other. Thus, the selecting and the selected dimensions may change positions and interact in a coevolutionary process of mutual shaping. In the case of the European information society, two major processes of reconstruction can be distinguished. First, there is the networking of the European Union in terms of institutional addresses. Among other things, the series of Framework Programs and other special programs have stimulated both transnational collaboration and collaboration across sectors. It can be shown that university-industry-government relations have gathered institutional momentum at the European level (Laredo 1997).
In addition to this level of networking, the new techno-sciences like biotechnology, new materials, and information technologies contain another network dynamics, namely, at the cognitive and therefore potentially global level. Gibbons et al. (1994) have coined the word "Mode-2 research" for areas like biotechnology. The applicational contexts are considered constitutive of the development of these fields. Thus, the triple helix of university-industry-government relations is not only an institutional, but also a substantive development (Etzkowitz & Leydesdorff 1997). From the global perspective, the European policies construct an intermediate network layer among some of the competing agencies.
In summary, one expects a double-layered construction of networks which fullfils the conditions of autopoiesis in the European case. Can the self-organization of the communication in this case be indicated by using literature-based indicators? In this study, we explore this question by limiting ourselves to "biotechnology" as a typical "Mode-2" field, and by assuming a competition at the global level between the emerging European networks, on the one hand, and the American and Japanese research efforts, on the other. [2]
Of course, there are many more countries in the world than these three
industrial blocks, but we know from previous research that including more
countries is not always helpful from an analytical perspective. For example,
including Canada makes it more difficult to distinguish between the U.S.A.
and Europe because of this country's position between the U.S. and the
U.K. research systems (Leydesdorff & Gauthier 1996). In this study,
we analyze biotechnology at different levels of aggregation in order to
better understand the possible emergence of a specific European level (cf.
Leydesdorff 1992).
2. Operationalization of the research question
We hypothesized above the interaction of two operating systems: the European network and the techno-science network of biotechnology. In general, the operating systems structure the variation by selecting; the observable variation can be considered as a result of their interaction or, more technically, as a window of mutual information. If the (co-)variation is repeated over time, a co-evolution can be induced along a trajectory. Trajectories can be selected recursively by a self-organizing regime (Maturana and Varela 1980 and 1984; Dosi 1982).
In order to operationalize these concepts, one has to distinguish the selecting operations analytically. In this design, we use the major biotechnology journals as a representation at the field level. In a next section, we shall explain how we made this selection using aggregated journal-journal citations as listed in the Journal Citation Reports (JCR) of the Science Citation Index (SCI). We used the latest available update at the time of the original data collection (July 1998), that is, the JCR of 1996. When the JCR for 1997 became available (November 1998), this CD-ROM could be used to replicate our analysis.
The European dimension can be operationalized in terms of the institutional addresses of the retrieved documents. All papers with an address in one of the fifteen member states are selected. Similarly, an American and Japanese dataset was generated for the sake of comparison. In the case of internationally co-authored papers we attribute the paper in full to each of the implied nations (so-called "integer counting").[3] Note that by using this design, the cognitive selection and the institutional selections are analytically independent.
In summary, the research question can be formulated as follows: can one use the scientometric data of the Science Citation Index in order to show self-organization as a complex dynamics in the case of both social and cognitive transformation processes? In this case, we have the ongoing reorganization of the European S&T system by processes of transnational collaboration, and the transformation of the sciences involved in "biotechnology" by the global transition towards Mode-2 research. These two dynamics are expected to interact.
Is it possible to show an effect in the European case which is different
from the American and Japanese cases? The global dynamics are expected
to be stabilized within the national dimension in these latter systems,
whereas the inter-European dynamics provides the participants with an additional
degree of freedom (Frenken 1998). Does this additional degree of freedom
make a difference that can be measured?
3. Methods and data
3.1. Delineation of the domain
The definition of "biotechnology" itself has changed in recent decades (OECD 1988). If one follows the actors historically (Latour 1987), one obtains a reflexive understanding about how these definitions have changed (e.g., Nederhof 1988). From an evolutionary perspective, however, one expects that some of these historical elements have been carried over into the current understanding, while other elements may have faded away. The self-organizing system is reflexive with reference to its historical manifestations. The modus operandi of this system therefore remains hypothetical.
The evolutionary perspective is obtained by focussing on the operation of the system in the present. On the basis of previous research, we conjectured that Biotechnology and Bioengineering could be considered as a leading journal in this field (Leydesdorff & Gauthier 1996). Using this seed journal as an entrance to the Journal Citation Reports of the Science Citation Index for 1996, a relevant journal environment was delineated by taking all journals into consideration that cited this journal or were being cited by it to the extent of one percent of its total citations. These aggregated citation relations were organized in a matrix which was then factor analyzed.
The eigenvector representing "biotechnology" consists of the thirteen journals made visible in Figure 1. Among these thirteen journals, Biotechnology and Bioengineering not only has the highest impact factor of the set, it also has the highest factor loading on the factor indicating biotechnology. It can therefore be considered as a "central tendency journal" in the citing dimension, as defined by Cozzens & Leydesdorff (1993).[4] With hindsight, this legitimates the initial selection of Biotechnology and Bioengineering as the starting point for the analysis.
Figure 1 provides a mapping of the relevant journal environment
in 1996. As expected, "biotechnology" is located between the fields of
"applied microbiology", "biochemistry / molecular biology," and "chemical
engineering". Furthermore, the journals
Water Research and the Journal
of Chromatography A are present as isolates in this environment. A
smaller subset relating to Biotechnology and Bioengineering at only
the 2%-level of total citations is indicated by using boldfaced characters
both within the map and in the legend.
3.2. Delineation of the domain in terms of documents
In 1996, the thirteen journals delineated as a biotechnology cluster contained a total of 1982 documents. In order to limit the computation given the exploratory nature of this project, we used only the five journals which had an aggregated citations relations above a 2% threshold to the core journal Biotechnology and Bioengineering.[5] These five journals contained 1023 documents in 1996.[6] Of these documents, 711 contain a European, Japanese, or American address.[7] Because of international co-authorship relations in these documents, there is a total of 787 country addresses.
We shall use these 787 records as the basis for the institutional analysis. The underlying document set (of 711 documents) contains 9,626 title words, of which 2,427 are unique. Of these words, 245 occur more than five times.[8] These 245 words were conveniently used as variables, since in some of our routines we have a software limitation of 256 (= 28) columns. However, nine documents in the set of 787 records with institutional addresses did not contain any of these 245 words, and were therefore not included in the analysis. Thus, a matrix of 778 cases and 245 variables was constructed in which each row can be read as a representation of the frequently used words and co-occurrences of words in the title of the corresponding document.
The words and their co-occurrences will be considered as the observable
variation. As the reader may easily see, a similar matrix can be constructed
using, for example, the most frequently occurring citations in this document
set. Citations, however, are already codified as textual elements. By using
words and their co-occurrences, one observes the intellectual space as
represented in the textual domain in the widest of its ramifications (Leydesdorff
1989; Leydesdorff & Wouters 1999).
3.3. Multi-variate analysis
How is one able to analyze this intellectual space of 245 words and co-words? Using the idea of co-occurrences of words as indicators of intellectual organization, the matrix of words and documents can be factor analyzed with the words as variables. The factor analysis provides us with a representation of the structure of the network of words. Each word has a position in the multi-dimensional network of co-occurrences among the words. This position can be expressed in terms of factor loadings representing the coordinates of each point.
Do these datapoints occur in clouds, or more evenly scattered over the multi-dimensional space? This assessment is crucial for the interpretation. The corresponding problem at the operational level is to determine how many groupings one should distinguish. What is the dimensionality of this space, and how can one provide it with an interpretation? As the structure becomes more pronounced, the choice of the dimensionality can increasingly be warranted.
Along the other dimension of the datamatrix, that is, the rows, one can analyze the cases in terms of the underlying structures using the institutional addresses. Since the institutional addresses are known ex ante, one may use discriminant analysis for testing. The title words are then considered as independent variables for predicting group membership, and one is able to assess the quality of this prediction. Discriminant analysis is akin to factor analysis since both techniques are based on eigenvector-analysis and parametric statistics.
We shall pursue discriminant analysis below, first, for the three industrial blocks of the E.U., the U.S.A., and Japan, and then for the 14 European member states (fourteen since there were no papers with an address from Luxembourg in the sample). In a next step, we combine the results of the factor analysis and the discriminant analysis in order to specify the coupling of the two distinguished operations in terms of self-organization theories.
The specification of expectations will enable us to proceed from the results of first-order data analysis to second-order theorizing. While the scientometric analysis is based on mapping and the induction of inferences about structures on the basis of observable variations, the operation of different (hypothetical) structures upon each other cannot be observed directly. However, one is able to specify the ways in which the results of the data analysis are significant in distinguishing among the various possible configurations.
For example, if the three blocks (E.U., U.S.A., and Japan) proved to be completely discrete in terms of the (combinations of) words used, one would expect a match between a three factor solution and the lists of words which are specific to each of these regional blocks. However, we anticipate also interaction among the regional blocks. If the three blocks were completely coupled at the global level, one would expect, in addition to the specific word sets, a common word set to be represented by another factor. Thus, in this case a four factor solution might provide the best fit, or perhaps a solution in which we allow for a single (global) factor only.
In practice, one expects a situation between complete coupling and complete
discreteness, and then more than four factors are expected. Having not
yet provided the reader with the results of the factor and the discriminant
analysis, this specification may become rather abstract. Thus, we return
to the methodological aspects involved in the next step after the discussion
of the results of scientometric analysis of the data.
4. Results of the scientometric analysis
4.1 Results of the factor analysis
Exploratory factor analysis of the variables informed us that words and co-words are not specific enough to provide us with useful information about the eigenstructure of this matrix. Figure 2 exhibits the scree plot of the eigenvalues against the number of factors. This indicates that 99 factors have an eigenvalue larger than unity and thus explain more of the variation than the average variable. This is a poor result. It means that the (245) words and their co-occurrences do not exhibit structure in general, and that the choice of the dimensionality of a factor solution (that is, the number of groupings of words) could only be arbitrary.
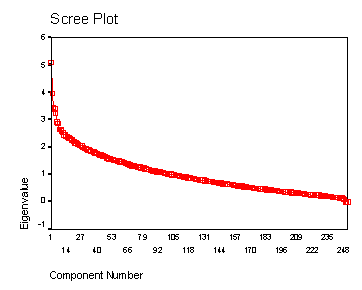
Figure 2
Scree plot of the eigenvalues in the network of 251
words and their co-words.
(102 eigenvectors have an eigenvalue larger than one.)
The problem of the arbitrariness of choosing a threshold is well-known in scientometric analysis of citation and co-citation data. Small et al. (1985a and 1985b) have proposed "variable level clustering" in the case of co-citation data. As noted, because of the implied selections, citations are an order of magnitude more specific than words. Citations are codified, whereas words can be provided with different meanings even within restricted document sets (Leydesdorff 1989 and 1997; cf. Amsterdamska & Leydesdorff 1989).
In summary, we used the highly restricted domain of a core set of five
journals in biotechnology. Nevertheless, the multi-variate analysis of
the (co-)word network did not provide us with reliable information about
the intellectual organization of the (biotechnology) network. The failure
to specify inductively the number of relevant dimensions further legitimates
a deductive approach to this uncertainty based on second-order theorizing
in a later section. For this purpose, we will then focus on the first ten
factors (which have eigenvalues larger than 2.5).
4.2 Results of the discriminant analysis
Using the attribution of the 778 American, Japanese, and European cases as a grouping variable, a fit of 77.6% correctly classified papers is obtained when using discriminant analysis (Table 1). By using simulation techniques, it could be shown that this level of discrimination cannot be considered statistically significant (Van den Besselaar, personal communication). There remains considerable uncertainty in the overlap which indicates the interaction at the global level.
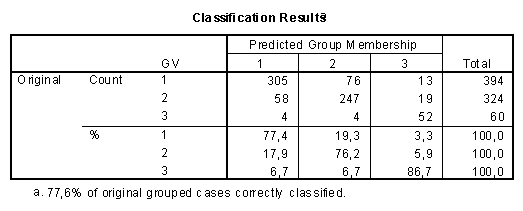
Table 1
Classification Results of Discriminant Analysis of
European (1), American (2), and Japanese (3) Addresses
In other words, the use of words and co-words is sufficiently different to enable one to distinguish among three sets of papers for which the institutional addresses (in the E.U., the U.S.A., or Japan) were correctly predicted, although the overall structure of the datamatrix in terms of words and co-words does not correlate with this division. As noted, this structure had also remained unclear in terms of the results of the factor analyses. Thus, one has no a priori grounds to assume any correlation between the word distributions in the three sets of papers and the word structure in the overall matrix. In a later section, we will test these correlations for their significance.
The three sets of papers provide us with specific representations in terms of occurrences of words and co-words. Using a geometrical metaphor one may envisage partly overlapping projections of the multi-variate space on the respective geographies. The all-group scatter plot exhibits the relative differentiation of the three groupings (Figure 3). In summary, the words and co-words in the ("biotechnology") document set did not reveal an inner logic that structures them (in terms of eigenvectors of their network of relations), but the geographical conditions provide an ex ante criterion enabling us to remove the misplaced records.
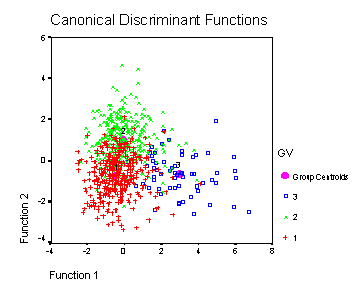
Figure 3
Scatter plot of groups of papers with European (+),
American (x), and Japanese Addresses.
5. A second-order test for self-organization
Let us resume the analytical argument. The words and co-words have been considered as the variation. On the one hand, this variation is conditional upon the initial selection of a core set of "biotechnology" journals. On the other, the variation is structured in terms of geographical addresses. Thus, two structures are hypothesized in this operationalization: a journal structure and a geographical structure. These two hypothesized selections operate upon each other and the result is an observable variation.
The variation is observable as the values in the cells of the matrix. The rows and columns of the matrix represent the selecting structures: the intellectual organization in terms of words versus the institutional organization in terms of document addresses. The (co-)variation between the axes can then be considered as a window through which these two structures communicate. As far as the two distributions do not interact, they only condition each other.
How can one indicate the relation between the observable coupling and the two hypothesized structures? As noted, the interaction between the two selections, that is, the observable variation is insufficiently structured for an inductive inference using multivariate analysis techniques. Let us turn to theorizing for a hypothetical specification of the interaction between the multi-variate space of the intellectual organization and the geographical spaces of each of the blocks.
If the three geographical regions were completely different, one would expect (as noted above) a representation of the intellectual domain in three groupings to provide a fit with the specific representations of the three regions. In Kauffman's (1993) terminology, one assumes three units (N = 3) and no links between them (K = 0) in this case. A three-factor solution should then provide a best match with the three separate word frequency lists using the correctly classified cases.
At the other extreme, if the three regions were completely coupled (N = 3 and K = 2), there would be an international dimension in addition to these three geographical dimensions, and a four-factor solution is expected to provide us with a best fit. The question then becomes the position of the global factor in relation to the geographically identified factors. Would a single factor solution also provide a fit?
Finally, if the three regions are differently coupled and/or in different dimensions (N = 3 and 0<K<2), one would expect more factors than four. In addition to the geographical organization, the intellectual organization is then supposedly differentiated in its selective operations. Consequently, one would expect interference, perhaps enabling us to distinguish between dominant patterns in the American-Japanese relation and/or the European-American dimension.
In operational terms, we can make a representation of each of the three regions in terms of the word-frequency distribution in the specific sets of papers which were correctly classified (by using discriminant analysis). The factor analysis of the whole set provides us with loadings for all the words on the various factors, and we can compare these factor loadings with the word frequency tables while forcing different numbers of factors. Thus, one is able to develop a test of the above reasoning. The test is against the odds, because the first-order instruments of multi-variate analysis were only weakly successful in making the relevant distinctions.
In summary, three situations can be distinguished:
2. if there were additionally an international dimension, the four-factor solution would exhibit the highest correlation;
3. a number of factors larger than four would show the highest correlation if a more complex arrangement were expected.
Figure 4 exhibits the results of this analysis using Pearson correlations between word frequency listings for the regional sets of documents and factor loadings for the respective number of factors being forced upon the factor analysis.[9] First, the three regions share a pattern of a better fit in the case of a growing number of factors, that is, in relation to a more complex semantic structure of words and co-words. Remember that we are reducing a structure of 245 words into a limited number of latent dimensions.
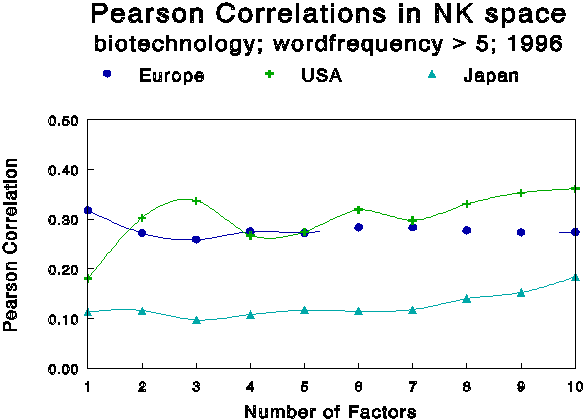
Figure 4
Pearson correlations between Word Frequency Lists
and Factor Loadings for a variable number of factors.
The American word distribution in particular fits better if we assume a more complex word pattern in the global distribution. The Japanese word distribution does not correlate significantly (p < 0.01) with any of the factors until nine or more factors are forced. As expected because of the noted overlap, the Japanese, American, and European word distributions are significantly correlated among themselves.
Both the American and the European set correlate significantly to the
principal component in the case of a single factor solution. When more
factors are forced, the solutions can be rotated (using Varimax) and therefore
the interpretation is more meaningful. In the case of two factors, the
European set correlates significantly with both factors one and two, but
to a higher extent with factor one (see Table 2). Factor two correlates
highest with the American repertoire.
|
EU USA JAPAN
factor 1 .2715** .1040
.0856
EU USA JAPAN factor 1 .2585** .0352
.0922
EU USA JAPAN factor 1 .2750** .0536
.1079
N of cases: 245 1-tailed Signif: * - .01 ** - .001
Table 2 Pearson correlations for two, three, and four factor solutions with the word distributions in sets of correctly classified documents. |
This configuration of two main factors dominates the solution until more than six factors are allowed. The internal differentiation of the sets, which becomes significant when forcing four factors, gradually becomes more important than the differentiation between the European and the American sets. In summary, the European vocabulary correlates significantly with the global vocabulary, but this shared vocabulary correlates more highly with the American one. The European vocabulary correlates additionally with a factor that has no significant correlation to the American repertoire.
In terms of our hypothesis, the results in Figure Four suggest
that the three-factor solution makes the American set somewhat more correlated,
while this configuration has a depressing effect on the European correlation.
In the case of a four-factor solution, the highest correlations for these
two sets are almost equal. As noted, these correlations are with two different
factors (that is, factors one and two, respectively). In summary, the European
vocabulary seems to be a bit more dominant (since loading on the first
factor), while the national embeddedness of the American vocabulary, which
is also significantly shared among the two groups, becomes visible in the
case of forcing three factors. The Japanese set couples only when the American
set becomes further differentiated, that is, in relation to specific dimensions
of the global repertoire.[10]
5.2 The European decomposition
Perhaps the European Union should be considered as a collection of national systems which, as an aggregate, is able to have an impact at the international level more than as a network. For the purpose of this analysis, the subset of documents with a European address can be decomposed in terms of the nation states that constitute the European Union. Since there were no papers with a Luxembourg address in this set, the N = 14.
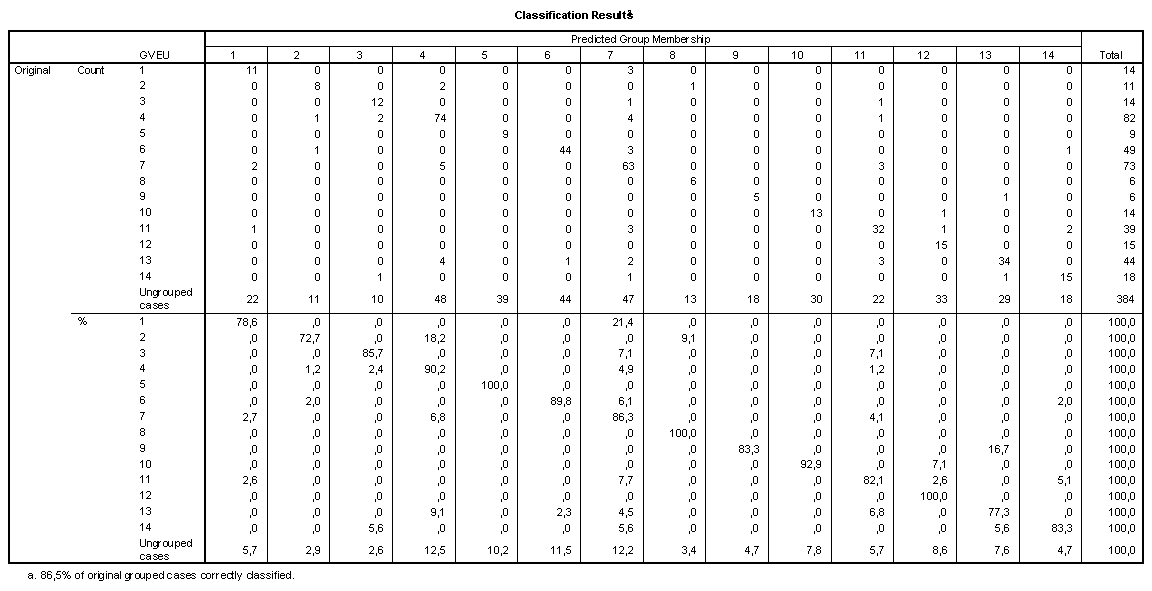
The discrimination of papers using the national addresses as discriminating variables is correct in 86.5% of the cases. The classification table is provided in Table 3. Note that 21.3 % (that is, three of the 14) papers with an Austrian address are predicted as of German origin. Belgian papers, on the other hand, are most difficult to predict in terms of the words used in their titles. The prediction is 100% correct for papers with a Finnish, Greek or Portuguese address.
| 1. Austria | 8. Greece |
| 2. Belgium | 9. Ireland |
| 3. Denmark | 10. Italy |
| 4. England, Scotland, Wales
and Northern Ireland (UK) |
11. Netherlands |
| 5. Germany | 12. Portugal |
| 6. France | 13. Spain |
| 7. Finland | 14. Sweden |
Table 3
Classfication Results of document sets for 14 member
states of the European Union
(Luxembourg excluded)
The fit between the word distributions in the correctly classified national sets and the factor solutions can be made visible by repeating the analysis of the previous section, mutatis mutandis. The curves for the 14 European countries are shown in the two Figures 5a and 5b (for seven member states each). Upon visual inspection, no general patterns seem to be discernable. Some countries (e.g., Austria) exhibit a better match when a larger number of factors is taken into account, while others (like the U.K.) do better in the range of lower numbers of factors. Denmark has a high profile over the whole range, followed by the U.K. and Sweden. While all couplings with an r > 0.2 are statistically significant, the French set is never significantly coupled.
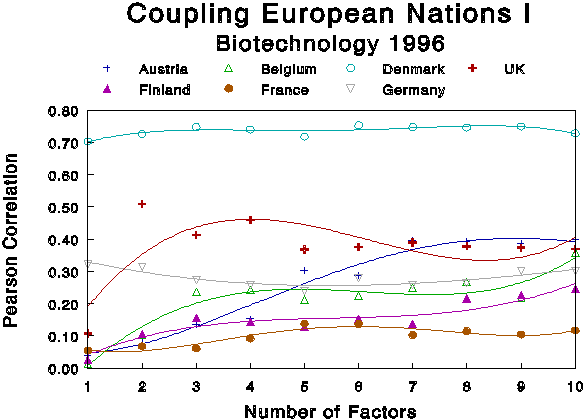
Figure 5a
Pearson correlations between Word Frequency Lists
and Factor Loadings for seven European nations given different numbers
of factors.
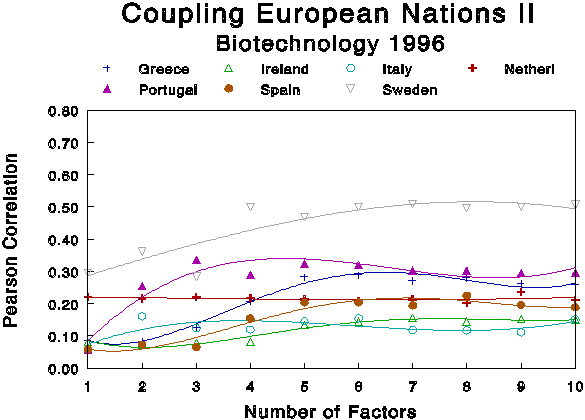
Figure 5b
Pearson correlations between Word Frequency Lists
and Factor Loadings for seven European nations given different numbers
of factors.
There are strong arguments from the literature to assume that the European nation states are stable configurations (Skolnikoff 1993; cf. Leydesdorff 1992).[11] In terms of the new evolutionary theorizing, one would formulate that the national systems occupy specific local optima (e.g., Kauffman 1993). However, given the number of relations among European member states, the landscape may be rather flat at the network level despite existing differences in national patterns. The various countries are sometimes positioned similarly in relation to the rest of the world.
For example, one can reasonably assume that from an American perspective, collaboration with a Danish or an Austrian partner does not make that much of a difference. Co-authorship relations with American colleagues may outnumber international co-authorship relations within Europe. This communality may help to reinforce the unification of Europe because of structural equivalencies (Burt 1982). These relations, however, are shaped at the level of individual authors and institutes.
Our argument has been that European development is entrained by the eigendynamics of the transient between two optima, that is, a global communication system shared with the Americans, and a differentiation within this system between the American and European repertoires. Although the European repertoire is significantly correlated to the factor solutions as an independent factor, its disaggregation into national repertoires exhibits important differences.[12] The self-organization of the European information society should not be considered as a local, but as a global phenomenon. At this global level, the number of local optima for the system is limited.[13]
In summary, there is systemness in the European repertoire, but the
main component of the variation is the aggregation of and not the interaction
among the national repertoires. Europeanization can from this perspective
be considered as a process of self-organization: an intermediate level
is constructed which can be retrieved as relevant at the global level,
but which itself is dominated by the dynamics of its subsystems.
6. Further extensions
Without further testing, these interpretations remain based on a single
measurement point, that is, "biotechnology" in 1996. Given this limitation,
it seemed useful to extend the analysis using 1997 data. In a second extension,
we will vary the threshold in the word frequency as one of the other parameters.
6.1 Comparison with the 1997 data
The publication of the Journal Citation Reports for 1997 enabled us to update the analysis. We pursued the analysis both for the same journal set as used in 1996 and for the revised journal set, that is, based on a new journal-journal citation analysis.
Compared with 1996, the Journal of Chemical Technology and Biotechnology maintained in 1997 an aggregated citation relation with the core journal (that is, Biotechnology and Bioengeneering) at the 2% threshold level, while the citation pattern of the Journal of Biotechnology was now sorted within the "applied microbiology" group using factor analysis. Thus, there is considerable development from year to year at this level of aggregated journal-journal citations.
Figure 6 exhibits a picture analogous to Figure 4 for the updated journal set. The American distribution is much more dominant in this case than in the previous one, and the main structure is the opposition between the American and Japanese sets. These two word sets correlate on the same factor, but with an opposite sign. The European set is significantly correlated only when six or more factors are forced, that is, after the internal differentiation of the American correlation pattern (which is reached at the five-factor solution).
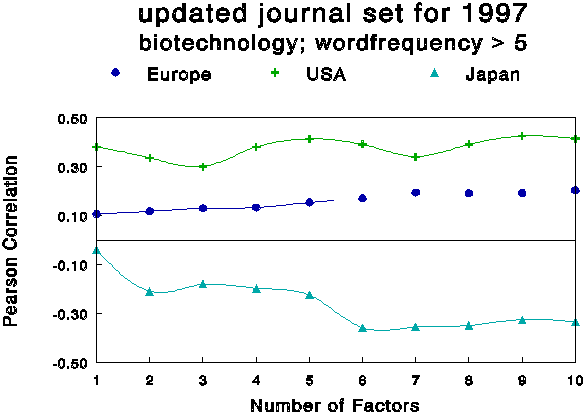
Figure 6
Pearson correlations between Word Frequency Lists
and Factor Loadings for different numbers of factors in 1997.
When the unchanged journal set of 1996 is used, the differences are less pronounced. The European set remains significantly coupled to the solutions with three or more factors, but at a lower level than the Japanese set. The decomposition of the European set into the nation states shows less variation when using this fixed journal set, while the variation remains more similar to the results for 1996 when using the updated journal set. In summary, the results suggest that the updated journal sets provide us with more information about the dynamics of the system than the analysis using the fixed journal set.
The more pronounced visibility of the Japanese factor in 1997 is not
an artifact of the relative number of papers in the 1997 set in comparion
to the 1996 set. Based on the updated 1997 journal set, 719 records containing
addresses in the E.U., the U.S.A., and Japan can be retrieved, of which
700 are included in the analysis (using 228 words which occur more than
five times). Of these 700 records, 47 or 6.7% contain a Japanese address
as against 60 out of 778 or 7.7% in the previous case. However, it would
lead us away from the research question of this study to pursue the analysis
of the variation in the coupling of the different Japanese document sets.
6.2 Variation in the word frequency threshold
Another parameter which we are able to vary is the number of words included in the analysis. By setting a higher threshold for the selection in this dimension, the substantive differences are expected to become more pronounced, while the European level would hardly be affected if this network is mainly institutional. This expectation is confirmed by the results exhibited in Figure 7.
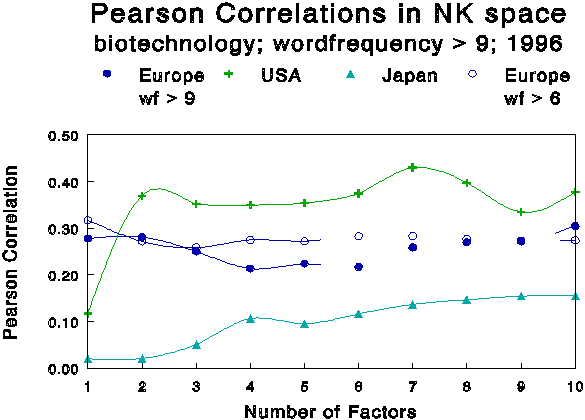
Figure 7
Changing the threshold level to wordfrequencies larger
than nine.
In this case, the analysis is based on the 149 words which occur more
than nine times in the set. The curve for the European document set is
only marginally affected, while the American document set couples more
strongly to this more selective word set. This result suggest that the
European level provides an institutional effect that feeds back on the
underlying variation among the European national systems, but that it is
less important in the cognitive dimension since it is not sensitive to
this stronger selection of the title words.
7. Conclusions
Scientific communications are extremely well archived, and therefore we have a wealth of data at our disposal when we study the dynamics of the sciences and science-based technologies. Information retrieval has been developed particularly for studying scientific literatures, and elaborate methods were standardized by scientometricians during the 1970s and 1980s. In this study, we have tried to show how these data and methods can be used to address questions from a second-order systems perspective about the emergence and self-organization of the European information society.
The main thrust of our argument has been methodological. We could have used patent data instead of scientific publications (cf. Narin & Noma 1985; Narin & Olivastro 1992). However, licensing and patent practices are expected to differ among national innovation systems (Nelson 1993). Furthermore, a European Patent Office is in place. The development of a European repertoire significantly different from the American and Japanese ones at the level of global scientific communications, that is, within established journals, seems to us a stronger argument for a process of self-organization at the European level as a (partially) unintended consequence of ongoing developments (cf. Leydesdorff 1992).
We have argued that Europe is different from the U.S.A. and Japan in that it is going through transformation processes at two levels at the same time, but without a necessary coupling between them. The contingency of the coupling allows for the process of autopoiesis, in principle. First, there is the European unification process that is stimulated particularly in the area of new sciences and technologies through the large European programs. These programs use a political definition of a theme. The theme of a program may refer to an emerging area of science and technology as in the case of biotechnology. The substantive definition of the field, however, is beyond the control of the European Commission.
Developments take place in a global market, and definitions are codified within the relevant communities of scientists and engineers who carry the system of publications as authors and co-authors. Although one would expect translations between the two domains of policy making and scientific production, we did not find the observable variation to be significantly codified in terms of words and co-words. Yet, the two systems are supposed to disturb each other through these observable translations.
In the case of Europe, the translations are further complicated because of the different relations between national and supra-national levels. From an evolutionary perspective, one would expect the two transformation processes to reinforce each other only when they have reached the basin of an attractor or, in other words, when the various dynamics have begun to resonate. Our results indicate that the various European national contributions differ mainly in terms of the couplings of their respective repertoires to the global developments. Nevertheless, a significant European interaction level could be retrieved. The European repertoire seems to be fragile, since it is less pronounced in the 1997 dataset than in the 1996 one. The integration may be more institutional than cognitive, since it is less sensitive to raising the threshold of the words included than the American one.
These network dynamics may be constitutive of the emergence of biotechnology as a Mode-2 science in the case of Europe, while in the case of the U.S.A. and Japan these developments are more firmly integrated within their respective national systems of innovation (Giesecke, 1998 and forthcoming). Without further testing, these interpretations of the results remain speculative.
Let us finally return to the methodological contribution to theorizing about complex dynamics contained in this paper. We have argued that self-organization theory is a second-order type of theorizing: first, one has to analyze the observable data as variation in relation to structures responsible for the hypothesized selections. On the basis of the results of the first-order analyses of the data, one is able to test ideas at the second-order level provided that the first-order explorations are carefully designed for this purpose. From this perspective, self-organization remains a hypothesis.
The two types of analysis are of a different nature. Whereas no statistical significance could be retrieved inductively in the initial analyses of word patterns, these negative results did not prevent us from using word patterns in testing the second-order hypothesis. On the one hand, second-order theorizing has a more elusive character, since one proceeds on the basis of hypothetical "what if"-type of questions. Note that the uncertainties in using various instruments at two layers of analysis have to be multiplied (P * Q), that is, not added (P + Q).
On the other hand, we have put our hypotheses to a strong test by using
standard statistics based on parametric assumptions. Had we used non-parametric
statistics (like probabilistic entropy; cf. Leydesdorff 1995), we might
have found more precise results enabling us to go further in the interpretation.
The test of a European vocabulary in these title words, however, was significant,
and the disappearance of this commonality when one pursues the analysis
at the level of the collectivity of nation states was also significant.
8. Normative implications
When a multi-layered network structure is self-organizing its further development in terms of layers of recursive selections, the prediction of its further development may be counter-intuitive. The system can be considered as moving on the transient towards another attractor. The point of control of the reorganization itself can be at shifting places, since the development is expected to be controled in terms of the functionality for the momentum of this unintended development. The variable language of steering has to be replaced with a language of fluxes and the geometrical representation of a control center is correspondingly replaced with an algorithmic simulation of different levels of control that may operate in parallel.
If one assumes that "biotechnology" as a Mode-2 research system has incorporated its applicational contexts, the European system can be considered a fortiori as an amalgam of industrial, political, and scientific propulsions. Thus, one expects neither the science system nor the political system itself to be propelling, but the amalgamation with an industrial system in a Triple Helix or Mode-2 configuration (McKelvey, 1996 and 1997; Leydesdorff & Etzkowitz 1998).
The internal differentiation of the political dimension in a national and a supranational level creates room for further recombinations without sacrificing existing advantages. Thus, Europeanization enriches the system with options for niche creation. When the system of control itself can no longer be fixed, it can be allowed to fluctuate reflexively in order to stimulate the self-organization of the European information society. In such cases, a complex mixture of policy initiatives coordinated only loosely at various levels of aggregation may unintentionally enable research groups to make the adaptations required by their continuously changing environments.
return
to Leydesdorff's home page
Notes
1. TSER project PL97-1296. The project is coordinated with a project about "The Self-Organization of the Japanese Information Society (SOJIS)." We are grateful to colleagues within these projects for stimulating discussions.
2. In a related project, comparable events in the case of information science are analyzed (Van den Besselaar & Heimeriks 1998; cf. Van den Besselaar & Leydesdorff 1996).
3. Integer counting has been distinguished in the scientometric literature as an alternative to fractional counting (Narin 1973). In the latter case, a relative weight is attributed in accordance with the number of co-authorship relations. See for a discussion: Anderson et al. (1988).
4. "Citing" is considered as the evolutionary operator, while citedness indicates codification (Leydesdorff 1988). In the "cited" dimension, the biotechnology grouping contains only six journals, of which Biotechnol. Progr. is most representative. As indicated by its name, this journal reports results relevant to other disciplines. Given the applied character of the emerging field, however, the biotechnology journals draw upon existing disciplines twice as much as the latter draw on this group in terms of citations.
5. Bioprocess Engineering is not processed by the Science Citation Index in 1996, but the Journal Citation Reports indicate that it would also have qualified for the 2% threshold.
6. The set is composed of 969 articles, 24 reviews, 21 editorials, 7 corrections, and 2 notes.
7. This set contained 676 articles, 20 reviews, 12 editorials, two corrections, and one note.
8. Single character words, abbreviations, numbers, and the following words were removed from this list: an, and, at, by, for, from, in, it, of, on, onto, the, to. "Between," "under," and "with" were included in the analysis, since the use of these prepositions was sometimes specific. Furthermore, singulars and plurals of nouns and verbs were equated by removing the trailing "s" (Leydesdorff 1995).
9. We abstract from the sign of the correlation, since the factor loading may differ in sign depending on previously extracted factors in the same analysis. Pearson correlation were used because factor analysis and discriminant analysis are both based on parametric statistics.
10. Whether these specific dimensions correspond to specialties in biotechnology can be investigated by decomposing the significant correlations using information theory (Theil 1972; Leydesdorff 1995).
11. Using Kauffman's (1993) general formula, the number of local optima is {2N/ (N+1)} for K = N - 1. A system with N = 14 would then have more than 1000 local optima. In this domain, however, K is probably smaller. For example, in Table 2 the number of off-diagonal cells with a value larger than zero is 28 out of 182 (that is, 15.4%), indicating a K of the order of two given 13 possible links for each of the 14 countries.
12. The lower triangle of the correlation matrix contains (142 - 13) = 85 cells. Only 42 of these correlations are significant at 0.01 level. Thus, the fourteen word distributions for the national groupings are significantly correlated in less than 50% of the cases.
13. Since N = 3, the number of local optima would be {23/ (3 + 1)} =
2 if K = 2. As argued K is between two and zero, and probably above one.
The dimensionality of the system is expected to remain fractional.
References
Amsterdamska, Olga, and Loet Leydesdorff. 1989. Citations: Indicators of Significance. Scientometrics 15: 449-471.
Anderson, J., P. M. D. Collins, J. Irvine, P. A. Isard, B. R. Martin, F. Narin, and K. Stevens. 1988. On-line approaches to measuring national scientific output-- A cautionary tale. Science and Public Policy 15: 153-61.
Burt, Ronald S. 1982. Toward a Structural Theory of Action. New York, etc.: Academic Press.
Cozzens, Susan E., and Loet Leydesdorff. 1993. Journal Systems as Macro-Indicators of Structural Change in the Sciences. In Science and Technology in a Policy Context, edited by A. F. J. Van Raan, R. E. de Bruin, H. F. Moed, A. J. Nederhof, and R. W. J. Tijssen. Leiden: DSWO/ Leiden University Press, pp. 219-33.
Dosi, Giovanni. 1982. Technological Paradigms and Technological Trajectories: A Suggested Interpretation of the Determinants and Directions of Technical Change. Research Policy 11: 147-62.
Etzkowitz, Henry & Loet Leydesdorff (Eds.) 1997. Universities in the Global Economy: A Triple Helix of University-Industry-Government Relations. London: Cassell Academic.
Frenken, Koen (in preparation). A Complexity Approach to Innovation Networks. The Case of the Aircraft Industry (1909-1997. Paper presented at the Second Triple Helix Conference, State University of New York at Purchase, January 1998.
Gibbons, Michael, Camille Limoges, Helga Nowotny, Simon Schwartzman, Peter Scott, and Martin Trow. 1994. The new production of knowledge: the dynamics of science and research in contemporary societies. London, etc.: Sage.
Giesecke, Susanne. 1998. Die Triple Helix von Technologie, Markt und Staat. Innovationssysteme in der pharmazeutischen Biotechnologie. Ph.D. Thesis, Freie Universität Berlin.
Giesecke, Susanne (in preparation). The Contrasting Roles of Government in the Development of the Biotechnology Industry in the U.S. and Germany, Paper presented at the Second Triple Helix Conference, State University of New York at Purchase, January 1998.
Kauffman, Stuart A. 1993. Origins of Order: Self-Organization and Selection in Evolution. Oxford: Oxford University Press.
Larédo, Philippe. 1997. Technological Programs in the European Union. Pp. 33-43 in: Etzkowitz & Leydesdorff (1997).
Leydesdorff, Loet. 1989. Words and Co-Words as Indicators of Intellectual Organization. Research Policy 18: 209-223.
Leydesdorff, Loet. 1992. The Impact of EC Science Policies on the Transnational Publication System. Technology Analysis and Strategic Management 4: 279-98.
Leydesdorff, Loet. 1995. The Challenge of Scientometrics: the development, measurement, and self-organization of scientific communications. Leiden: DSWO Press, Leiden University.
Leydesdorff, Loet. 1997. Why Words and Co-Words Cannot Map the Development of the Sciences. Journal of the American Society for Information Science 48: 418-27.
Leydesdorff, Loet, and Susan Cozzens. 1993. The Delineation of Specialties in terms of Journals Using the Dynamic Journal Set of the SCI. Scientometrics 26: 133-54.
Leydesdorff, Loet, and Élaine Gauthier. 1996. The Evaluation of National Performance in Selected Priority Areas using Scientometric Methods. Research Policy 25: 431-50.
Leydesdorff, Loet and Henry Etzkowitz. 1998. The Triple Helix as a model for innovation studies. Science and Public Policy 25: 195-203.
Leydesdorff, Loet and Paul Wouters. 1999. Between Texts and Contexts: Advances in Theories of Citation. Scientometrics 44 (forthcoming)
Maturana, Humberto R., and Francisco J. Varela. 1980. Autopoiesis and Cognition: The Realization of the Living. Dordrecht, etc.: Reidel.
Maturana, Humberto R., and Francisco J. Varela. 1984. The Tree of Knowledge. Boston: New Science Library.
McKelvey, Maureen D. 1996. Evolutionary Innovations: The Business of Biotechnology. Oxford: Oxford University Press.
McKelvey, Maureen D. 1997. Emerging Environments in Biotechnology. Pp. 60-70 in: Etzkowitz & Leydesdorff (1997).
Narin, Frances, and E. Noma. 1985. Is Technology Becoming Science? Scientometrics 7: 369-381.
Narin, Frances, and D. Olivastro. 1992. Status Report: Linkages between technology and science. Research Policy 21: 237-49.
Nederhof, Anton J. 1988. Changes in publication patterns of biotechnologists: An evaluation of the impact of government stimulation programs in six industrial nations. Scientometrics 14: 475-85.
Nelson, Richard R. (Ed.), 1993. National Innovation Systems: A comparative study. New York: Oxford University Press.
OECD. 1988. Biotechnology and the Changing Role of Government. Paris: OECD.
Skolnikoff, E. B. 1993. The elusive transformation: Science, technology and the evolution of international politics. Princeton, NJ.: Princeton University Press.
Small, H., and E. Sweeney. 1985a. Clustering the Science Citation Index Using Co-Citations I. A Comparison of Methods. Scientometrics 7: 391-409.
Small, H., E. Sweeney, and E. Greenlee. 1985b. Clustering the Science Citation Index Using Co-Citations II. Mapping Science. Scientometrics 8: 321-40.
Theil, Henry. 1972. Statistical Decomposition Analysis. Amsterdam: North-Holland.
Van den Besselaar, Peter, and Gaston Heimeriks. 1998. The Self-Organization of the European Information Society. Paper presented at the EASST Conference, Lisbon, September/October 1998.
Van den Besselaar, Peter, and Loet Leydesdorff. 1996. Mapping Change
in Scientific Specialties: A Scientometric Reconstruction of the Development
of Artificial Intelligence. Journal of the American Society for Information
Science 47: 415-36.