Why Words and Co-words Cannot Map
the Development of the Sciences
Loet Leydesdorff
Science and Technology Dynamics
ASCoR, Kloveniersburgwal 48
1012 CX Amsterdam
The Netherlands
Telephone: +31- 20- 525 6598
e-mail: loet@leydesdorff.net
April 1996, preprint version
Journal of the American Society for Information Science 48 (1997, no. 5) 418-27.
Abstract
A restricted set of full-text articles from a sub-specialty of biochemistry was analyzed and compared in terms of co-occurrences and co-absences of words. By using the distribution of words over the sections a clear distinction among `theoretical', `observational', and `methodological' terminology can be made in individual articles. However, at the level of the set this structure is no longer retrievable: words change both in terms of frequencies of relations with other words, and in terms of positional meaning from one text to another. These results accord with Hesse's (1980) thesis about the sciences as fluid networks. The fluidity of networks in which nodes and links may change positions is expected to destabilize representations of developments of the sciences on the basis of co-occurrences and co-absences of words. The consequences for the lexicographical approach to generating artificial intelligence from scientific texts are discussed.
Introduction
Words and their co-occurrences have been considered as indicators of concepts and their associations (e.g., Hesse 1980; Callon et al. 1983; Kuhn 1984). But words occur within sentences which provide them with meaning (Bar-Hillel 1955). Sentences are probably the smallest meaningful units of textual structure in a scientific article: sentences can be considered as indicators of statements. Various statements contribute to the weaving of an argument; and the full knowledge claim of the article is organized in paragraphs and sections that can be analyzed also in terms of aggregates of sentences (Figure One). Thus, different levels of aggregation within and among texts can be distinguished. At higher levels of aggregation articles constitute oeuvres, journals, archives, etc. Cognitive organization (e.g., in terms of specialties) is expected to emerge at higher levels of aggregation of texts.
In this study, our approach of co-word analysis will be "bottom-up" in order to analyze the emergence of structural elements at higher levels of textual organization. The properties at the next-higher level can be analyzed as the latent dimensions of the network of relations among the lower-level units. Therefore, we first attribute words to sentences as units of analysis. From this matrix of sentences versus words new matrices can be generated by repetitive aggregation.[1] Figure One illustrates the process: at each higher level one can analyze the subsequent matrices with reference to the question of whether new structural properties are indicated. The structural properties ("eigenvectors") of the matrix represent the specific organization of the textual structures at the corresponding level of aggregation.
In a previous study I analyzed the latent structure of the full text of a single biochemistry article[2] using this model (Leydesdorff 1991). Two major but related findings from that study enabled us to propose a discriminant analysis model that will be tested below using a set of 17 biochemistry articles from a single subfield. First, the factor analysis of the words attributed as variables to the fours sections as cases led to a sharp and meaningful three-factor solution. These three factors indicate lists of words with decreasing factor loading on theoretical, observational, and methodological dimensions. This structure could not be found at lower levels of aggregation. Below, we shall examine the set of documents studied here on this property.
In itself, the fact that the variance can be explained by three factors is an analytical consequence of having only four cases, and hence three dimensions (see, e.g., Bray and Maxwell 1985). However, this does not explain why the structure is clear and meaningful. Dendograms (from cluster analysis) enable us to visualize the results of the factor analysis in anticipation of the results of this study. Figure Two exhibits a dendogram for one of the articles examined.[3] The distinction between the three relevant groups of words is clearly visible: from the left to the right we can see a cluster with words related to the observations being reported in the paper (e.g., found, slow, number), a second (internally more complex) cluster with words indicating the theoretical thrust of the paper (e.g., kinetic, membrane, affinity), and a third more distant cluster consisting of words related to methods (e.g., filter, ml, pH).
The distinctions are precise. For example, in the first instance, one wonders why `increase' is listed among the observational terms (in the first cluster), and `decrease' among the theoretical ones. If one looks into the text, one notes that `increase' is used by these authors in association with empirical achievements, while `decrease' tends to be associated with a theoretical inference. For example, the authors claim the following result:
"The binding activity per milligram of protein (at 10 nM cAMP) was increased 5.8‑fold (" 2.0) (n = 4) by the isolation procedure."
Among the conclusions, they formulate:
"Guanine nucleotides decrease the affinity of membranes for cAMP (Figure 8; Janssens et al., 1985; van Haastert, 1984). This effect proves to be the result of a decreased contribution of S and SS sites to total cAMP binding, rather than of a decrease in affinity of the S and SS receptor forms."
In addition to the word structure in a document or among documents, one can study also document structure(s). Discriminant analysis, for example, allows us to study the significance of the grouping of sentences at various levels of aggregation using the words as discriminating variables. A so-called scatterplot on the basis of the discriminant analysis of this same text is shown in Figure Three: the statistical attribution of 165 sentences to sections on the basis of word occurrences is correct in 163 (98%) of the cases. This order in the document corresponds to our intuitive understanding of the codified relations among the sections in scientific texts. For example, the sentences from the introduction ("1") are positioned on the theoretical side, but at the interface with observational statements; a few sentences relate the methodological issues ("2") with the other sections of the article.
The results of the factor analysis and the discriminant analysis are analytically related, but the one is not a logical consequence of the other. While the results of the factor analysis predict that the patterns of co-occurrences and co-absences of words are significantly different when the sections are taken as the units of analysis, the discriminant analysis shows that these `co-word' patterns are not a property of the article, but specific for each section. If words with different epistemological status are so differently distributed over the various sections of the articles, one expects to be able to rank-order the various types of words into different lists by using these various forms of multi-variate analysis.
In principle, lists can be used to develop artificial intelligence, since clauses can operate on lists using computer languages like PROLOG or LISP. The consequence of an analytical distinction between `theory' and `observation', however, would be at odds with an argument made in the neo‑conventionalist philosophy of science with relevance for the co-word model. Against logico-empiricism and critical rationalism, (neo‑)conventionalist philosophers have argued that scientific arguments are woven non-formally into scientific texts (e.g., Quine 1962; Hesse 1980). For example, the `network' of co-occurrences and co-absences of words is defined by Hesse (1980, at p. 86) as an essentially linguistic expression of the continuous integration of observation and theorizing in the sciences. The epistemological distinction between theoretical and observational descriptions is considered not one of kind but rather of degree.
Hesse (ibid., at p. 103) claimed that the pragmatic and nonformal use of predicates can be observed empirically in terms of the co-occurrences or co-absences of words (cf. Law & Lodge 1984; Collins 1985). In contrast to the empiricist and rationalist traditions which focus on the syntactic logic of theorizing, Hesse's networks are supposed to be knitted by `words'-predicates, names of entities-which have to be understood and used in positions relative to each other (ibid., pp. 64f). The above results suggest that one can reconstruct theoretical order with the help of (machine-readable) lexicographical tools, i.e. without the need of a syntactic or semantic analysis (cf. Callon et al. 1986). The organization of words with different semantics in the text is codified because of a linguistic sub-structure (e.g. Liddy 1988; Liddy et al. 1993). Callon et al. (1993) generalized this point by proposing co-words as `second-order scientometric indicators' which enable us to compare among different bodies of texts like conference papers, policy documents, and scientific articles. But are co-occurrences of words sufficiently codified for indicating also `translations' among texts?
The model
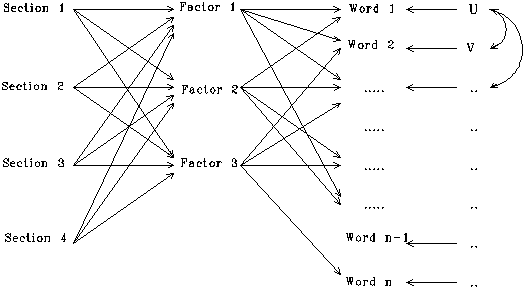
The discriminant analysis model which was inferred on the basis of the previous study is depicted in Figure Four: three factors (F1, F2, and F3)-which have been designated as `theoretical,' `methodological,' and `observational'-are hypothesized as latent variables which structure the relations among words.[4] However, since we found that the factors emerge only if we analyze at the level of the sections, the sections (S1, S2, S3, and S4) are considered as independent dummy variables.[5] (The letters U, V, etc., represent disturbance or error terms, i.e., relations among words which are not explainable in terms of the three factorial terms.)
Note that the notion of a word as a variable is reconceptualized in this model: in co-word analysis one uses words as nominal variables, which can either be attached to units of analysis or not; when conceptualized in this model, words have values on underlying dimensions. Because we study here the position of words in terms of their values on assumed (`latent') dimensions,[6] we are able to compare text with text despite the fact that other co-occurrences may be relevant. For example, we aim at comparing the words among texts with highests loadings on the factor `methods' as an indicator of change in this dimension.
Given the overall objective of the reconstruction of scientific developments in terms of machine-readable texts, the objective is to create lists of words for each text with decreasing `theoretical,' `methodological,' and `observational' values. As noted, in artificial intelligence lists constitute the databases from which the clauses operate. Thus, the creation of lists which can be designated dimensionally might solve part of the problem of how to engineer the knowledge without being oneself an active participant in the knowledge production and control process under study.
Sample choice
The starting-point for the present inquiry was an article by R.L. Bernstein, C. Rossier, R. van Driel, M. Brunner and G. Gerisch, `Folate Deaminase and Cyclic-AMP Phosphodiesterase in Dictyostelium Discoideum-Their Regulation by Extracellular Cyclic-AMP and Folic Acid' (Cell Differentiation 10, 1981, 79-86). The third author, Dr. Roel van Driel, is senior scientist at the Amsterdam laboratory of biochemistry; he acted as an advisor to the study reported here.
D. discoideum is a slime mold which functions as a model system for important biochemical processes in developmental biology. Under conditions of starvation individual cells of this species are able to register one another's presence by the secretion of `chemo-attractants.' Subsequently, the individual cells aggregate, form a multicellular organism, and start a well-defined developmental cycle, resulting in two differentiated cell types in a specific spatial arrangement. The substantive question of the biochemical research is: how do these cells manage to send and receive mutual signals in a controlled manner in order to coordinate biological action?
There is a steady amount of work being done on this problem worldwide, which results in a regular production of articles, on the order of magnitude of one hundred per year. Publication patterns are scattered: Developmental Biology, Cell Differentiation, and Molecular and Cellular Biology are among the more important journals in the area. Using the online installation of Biochemistry of the American Chemical Society (at STN),[7] 17 articles were found in the period 1982-1988[8] subsumed under Dictyostelium, in 15 of which this word also appeared in the title. Two others used Discoidin I in the title. Together with the noted article by Bernstein et al., this provided us with a sample of 18 articles. From the interviews with Van Driel, who co-authored two of these articles, I concluded that this highly restricted[9] sample (listed in Table One) provided me with also a sufficiently complete domain.
The full texts of 17 articles were downloaded from Biochemistry and stored on disk. The original article was additionally typed into a file.
Processing
For the analysis, only the body of the argument of the articles was used. Since we don't wish to beg the issue of a retrievable (sub‑)structure, all elements of what is sometimes called `para-text' in semiotics (like section headings, captions, footnotes, and acknowledgements) were excluded from the analysis. All words contained in the remaining full sentences were counted and organized in a database in terms of the sections in which they occurred. With the exception of adverbs derived directly from adjectives, all adverbs, numbers, pronouns, conjugations of `to be,' `to have,' `may,' `will,' `shall,' `can,' etc., (copulas and modal verbs) were excluded using a stop-list. Singulars and plurals were equated; comparatives and superlatives were replaced by the basic forms of the adjectives. Conjugations of verbs were equated only when the present indicative form would not lead to ambiguity with a corresponding noun. All one-letter abbreviations were excluded from the analysis. In the case of highly specialized nouns and adjectives, the two were equated (for example, `electrophoresis' = `electrophoretic'). In order to limit computation, only words which occurred three or more times in one of the articles were included.[10] The net result was a total of 1287 words, which occurred 28,422 times in the document set.
The processing provides us with a matrix of four sections ("Introduction," "Methods and Materials", "Results", and "Conclusion", respectively) versus the number of words in the analysis, for each of the articles. These 18 matrices were factor analyzed with the words as variables, and cluster analyzed with the words as the cases. Cluster analysis was mainly used to check for the existence of smaller clusters of words which could have been overlooked in the factor analysis that was based on the noted three-factor solution. Additionally, it provided visual information about the multivariate structure, while the factor-analytic results remain heavily numerical.
The words were organized as three lists on the basis of the results of the factor analysis. Factors were designated using the factor-scores of the four sections in the following order: the factor with highest value (as a latent variable) on the methods-section was indicated as `methodological,' the one with highest loading on the results-section as `observational,' and the one with highest loading on the discussion-section as `theoretical.'[11] As a criterion for the attribution of a factor to one of these functions in the article, the factor score for a given section should be more than ten times as large as the other factor scores. Thus, if the factor score for the methods section was > 1.0, all the other sections should have a score < 0.1 on this factor. In that case, this factor was designated as the methodological one. If necessary, signs were adjusted to the designation.[12] An example of a typical table of factor scores (again for the case of Janssens et al. 1986) is exhibited in Table Two. Note that the introduction section is not sufficiently specific on this criterion.
Results
On the basis of the criterion of a difference of one order of magnitude, factors in 17 of the 18 articles could be analyzed unambiguously in terms of the three hypothesized categories, and consequently, factor loadings could be sorted so that comparisons among texts of words along dimensions became possible. Figures Two and Three (above) already provided the reader with an illustration of the dendogram and the scatterplot for the Janssens et al. 1986 article. Similar pictures could be drawn in all other cases except for one.
In this one case, the Van Haastert 1987 article, the cluster of methodological words-which can be shown to exist using cluster analysis-proved to be less important in terms of eigenvalues than the fine-structure of the various parts of the wordset which indicates the theoretical argument of the paper. Thus, the three-factor solution fails to provide useful information. The methods section (13 sentences) of this article is small in comparison to the other sections, and the article has an extraordinarily long introduction in which the author reviews various theoretical positions in the specialty (31 sentences). This long summary of previous positions in the introduction uses a vocabulary which differs more from the theoretical repertoire used in the discussion section (44 sentences) than either of these differs from the methods section in terms of eigenvalues. Note also that this is the only article in the set which is single-authored.[13] Thus, this article is more in the nature of a review than a research paper. Since it failed on the criterion of factor designation at the section level, it was excluded from testing the discriminant analysis model.[14]
To what extent do the remaining 17 articles lend themselves to the task of generating lists of words with the indicated categorical meanings? The listings of words with attributed factor loadings can be compared for the three dimensions among the 17 texts: a matrix of (3 x 17=) 51 variables (i.e., factor laodings) and 1287 words as cases can be generated.[15] Considering the factors as latent dimensions for each of the articles, we can then raise the question of whether there is significant commonality within each of the dimensions (theory, methods, observations) among the articles. For example, while not every article will report on `centrifugation,' those which do are expected to do so in the dimension of methods mainly, and not at variance over dimensions. Of course, some other words may change their positions, but we would expect this to happen against a stable background.
However, this was not the case! For example, among the 95 words in our sample which begin with the letter `A,' 39 (i.e., 41%) load on factors representing different dimensions in at least one article. Not only the more trivial words, but also central terms exhibit such variation among factor loadings for different articles. Examples of such words include not only, `ability,' `absence,' `absorbance,' `acetate,' `acid,' `activate,' etc., but also highly specific words in this context like `aggregation,' `amoeba,' `association,' `AMP' and `ATP.'
All kinds of combinations occur, also among the three dimensions. Explorative correlation and factor analysis of the matrix of factor loadings (3 x 17= 51 variables) teaches us that correlations were highest among factor loadings representing the methodological dimension (Table Three). As noted above when discussing the dendogram in Figure Two, this dimension is the most specifically codified in each article. Not surprisingly, there is the highest correspondence among the articles in this dimension (75.6% of the correlations among articles are significant at the 0.01 level). However, the interaction in terms of word occurrences between this dimension and the theoretical dimension (31.9%) is even larger than the stability in either the latter or the observational dimension (17.6% and 28.6%, respectively).
Thus, further analysis reveals that words in the methodological and the theoretical dimensions interact semantically over the set, while words indicating observations are somewhat separate. These results are in accordance with what one would expect: methodological terms are the most clearly defined; disagreement arises more readily around theories and the terms they use. The (sub-structural) boundaries among theory and methods may change. Empirical results are of various kinds, since the different articles do not study the same aspects of D. discoideum, but observational terms do not easily change places with theoretical or methodological ones.
Among the documents in the sample are five with (co-)authorship links between them. Are they more consistent in word usage than the others? Indeed, correlations between lists of factor loadings are always signifcant at the one percent level for the methodological and the observational dimension. But they are not in two out of five in the theoretical dimension. Obviously, the same author can use comparable methods and domains in different theoretical contexts.
In summary: although many words occur in various sections of the text, by using the distribution of words over the sections of each individual article a clear pattern in the noted three dimensions could be retrieved (with the one exception mentioned above). However, at the level of the set this structure is no longer present: a substantial number of the words will tend to hold one position in terms of these three dimensions in one text, and another one in another text. The main conclusion, therefore, is that the dimensions cannot provide a stable background of (latent) patterns of co-occurrences and co-absences which can be used to indicate change in terms of (co‑)occurrences of words. Words change position not only in terms of the dimensional scheme of `theory,' `methods,' and `observational results,' but they also change in meaning from one text to another. The codification of meaning identifiable in one text breaks down if one generalizes among more texts, even within this narrowly defined subject area.
Conclusions
Paradoxically, the refutation of the discriminant analysis model accords with Hesse's (1980) philosophical thesis about the sciences as fluid networks, while the co-word model for comparisons among scientific texts was originally legitimated in terms of this philosophy (e.g., Law & Lodge 1984; cf. Collins 1985). Not only do the nodes and the links of the network change, but what counts as a node and what counts as a link may differ among theoretical perspectives, and also change over time. What may be a useful term for a theoretical concept in one context may be used much more as an observational term in the context of another article. We may conclude from the above results that such changes occur also in the very micro-structure of a scientific specialty, i.e. at the level of comparisons among articles in a highly restricted document set.
While word usage is codified within each individual article, the various articles are not comparable in terms of the words indicating the latent dimensions which the factor analysis revealed. As a consequence, the analyst is not able to distinguish empirically how much of the observable variation is dependent on change in terms of the changing positions of individual words against a more stable background vocabulary (Hesse's `links'), or on change in the vocabulary itself, i.e. in the way it attaches to the description of reality (Hesse's `knots'). At the set level one finds change both in terms of how words are used and in terms of what words stand for conceptually.
Not only the words which indicate the `knots' and the `links'-with potentially different epistemological status-may change position in terms of their functions in texts, but also their distributions-i.e., their co-occurrences and co-absences. The networks are fluent both in their development over time and in terms of variations in perspectives at each moment. Furthermore, the distribution of word usage at the set level contains a considerable `intertextual' interaction, which can be measured as an in-between group variance when the texts are aggregated to the set (cf. Leydesdorff 1990a).
If both the categories and the values of the variables are in flux, one needs a calculus in order to understand their development. Already in 1955, Bar-Hillel hinted at the possibility of an information calculus enabling us to understand the statistical interpretation of word occurrences and their meanings in a single research design. While the multivariate analysis allows us to draw `scientometric mappings' at different levels of aggregation and at different moments in time, the representation in each of the maps remains static. Information calculus allows us to develop integrated models for the dynamics of science at different levels of aggregation (Leydesdorff 1995; cf. Theil 1972).
Consequences for the lexigraphical approach
The subsumption of phenomenologically similar words or other textual signals under keywords or other concept symbols assumes stability in the meanings of the indicated concepts. One major implication of the considerations in this study for the longer-term purpose of generating (`second-order') expertise or artificial intelligence from (co-)word relations among scientific texts is that the assumption of the conceptual stability of terms over texts is more problematic than has often been assumed in declarative knowledge engineering, thesaurus construction, and indexing.[16]
The fluidity of epistemic networks in which nodes and links change positions may destabilize any knowledge representation on the basis of co-occurrences of words. The usual distinction between the data stored in a knowledge base, such as the archived literature, and the inference engine is problematic when applied to scientific texts, since with the choice of a theoretical perspective not only the relative weights of various pieces of data may change, but the `rules of the game' can also be affected. Sciences are not haymaking machines which collect facts according to standardized procedures, but developing conceptual apparatuses. Accordingly, (co‑)words are embedded in changing contexts (cf. Lesk 1969; Salton 1970). A declarative knowledge representation based on analysis of textual (co‑)occurrences is not able to account for the dynamics of the sciences at various levels of aggregation.
More generally, a knowledge representation is stamped by the time when it was engineered and framed. It attaches an analytical meaning to the events that are expected to occur. For example, the events can be evaluated from the perspective of an assumed sub-structure (Liddy 1989). But is one able to instruct the system when to give way to a different representation (cf. Leydesdorff 1992)? From this (evolutionary) perspective, an intelligent knowledge-based system is not essentially different from a textbook, although it may be additionally interactive and also have some capacity to learn. In the case of the sciences, however, the systems under study are specialized in systematic learning. In general, an intelligent knowledge-based system is expected to loose the competition in a universe which allows for inter-textual learning (Leydesdorff 1994).
References:
Bar‑Hillel, Y. (1955). An Examination of Information Theory, Philosophy of Science, 22, 86‑105.
Bernstein, B. (1971). Class, Codes, and Control. Vol. 1: Theoretical Studies in the Sociology of Language. London: Routledge & Kegan Paul.
Bray, J. H., & Maxwell, S. E. (1985). Multivariate Analysis of Variance. Beverly Hills, etc.: Sage.
Callon, M., Courtial, J.-P., Turner, W. A., & Bauin, S. (1983). From Translations to Problematic Networks: An Introduction to Co‑word Analysis, Social Science Information 22, 191‑235.
Callon, M., Law, J. & Rip, A. (Eds.) (1986). Mapping the Dynamics of Science and Technology. London: Macmillan.
Callon, M., Courtial, J.-P. & Penan, H. (1993). La Scientométrie. Paris: Presses Universitaires de France.
Collins, H. M. (1985). Changing Order: replication and induction in scientific practice. London: Sage.
Engelsman, E. C., & Van Raan, A. F. J. (1991). Mapping Technology. A first exploration of knowledge diffusion amongst fields of technology. The Hague: Ministry of Economic Affairs.
Granovetter, M. S. (1982). The Strength of Weak Ties. A network theory revisited, in: Marsden, P. V. & Lin, N. (eds.), Social Structure and Network Analysis. London/ New York: Sage, 105-30.
Healey, P., Rothman, H. & Koch, P. K. (1986). An Experiment in Science Mapping for Research Planning, Research Policy 15, 179‑84.
Hesse, M. (1980). Revolutions and Reconstructions in the Philosophy of Science. London: Harvester Press.
Jöreskög, K. G. & Goldberger, A. S. (1975). Estimation of a model with multiple indicators and multiple causes of a single latent variable, Journal of the American Statistical Association 70, 631‑9.
Kuhn, T. S. (1984). Scientific Development and Lexical Change, The Thalheimer Lectures. Johns Hopkins University.
Law, J. & Lodge, P. (1984). Science for Social Scientists London: Macmillan.
Lesk, M. E. (1969). Word‑Word Associations in Document Retrieval Systems, American Documentation 20, 27‑38.
Leydesdorff, L. (1987). Various Methods for the Mapping of Science, Scientometrics 11, 291‑320.
Leydesdorff, L. (1989). Words and Co‑Words as Indicators of Intellectual Organization, Research Policy 18, 209‑23.
Leydesdorff, L. (1990). Relations Among Science Indicators I. The Static Model, Scientometrics 18, 281‑307.
Leydesdorff, L. (1990). Relations Among Science Indicators II. The Dynamics of Science, Scientometrics 19, 271‑96.
Leydesdorff, L. (1991). In Search of Epistemic Networks, Social Studies of Science 21, 75‑110.
Leydesdorff, L. (1992). Knowledge Representations, Byaesian Inferences, and Empirical Science Studies, Social Science Information 31, 213-37.
Leydesdorff, L. (1994). The Evolution of Communication Systems, Int. J. Systems Research and Information Theory 6, 219-30.
Leydesdorff, L. (1995). The Challenge of Scientometrics: The development, measurement, and self-organization of scientific communications. Leiden: DSWO Press, Leiden University.
Leydesdorff, L. & Zaal, R. (1988). Co‑Words and Citations. Relations Between Document Sets and Environments. In: L. Egghe & R. Rousseau (Eds.), Informetrics 87/88 (pp. 105-19). Amsterdam: Elsevier.
Liddy, E. D. (1988). The Discourse-Level Structure of Natural Language Texts: An exploratory study of empirical abstracts. Ph. D. Thesis, Syracuse University, NY.
Liddy, E. D., Jorgensen, C. L., Sibert, E. E., & Yu, E. S. (1993). A Sublanguage Approach to Natural Language Processing for an Expert System, Information processing & management 29(5), 633-45.
Quine, W. V. O. (1962). Carnap and logical truth. In: Logic and Language: Studies Dedicated to Professor Rudolf Carnap on the occasion of his seventieth birthday. Dordrecht: Reidel.
Salton, G. (1970). Automatic Text Analysis, Science 168, 335-43.
Theil, H. (1972). Statistical Decomposition Analysis. Amsterdam/London: North-Holland.
Tryon, R. C. & Bailey, D. E. (1970). Cluster Analysis. New York: McGraw‑Hill.
Whittaker, J. (1989). Keywords Versus Titles as Data for Co‑Word Analysis, Social Studies of Science 19, 473‑96.
|
Basic matrix of sentences versus words
Word A B C D ... ... ... ... Z
Sentence 1 1 0 0 2 0 0 0 1 0 ) Sentence 2 1 1 0 0 0 0 1 1 0 ) Paragraph 1 Sentence 3 0 0 0 1 0 0 0 1 0 ) ..... . . . . . . . . . ..... . . . . . . . . .
Paragraph 1 is in this example the sum of the rows, representing sentences 1 to 3
Aggregated matrix of paragraphs versus words
Word A B C D ... ... ... ... Z
Paragraph 1 2 1 0 3 0 0 1 3 0 ) Paragraph 2 . . . . . . . . . ) Section 1 ..... . . . . . . . . . )
Further aggregated matrices of sections, articles, journals, etc. versus words
Word A B C D ... ... ... ... Z
Section 1 . . . . . . . . . Section 2 . . . . . . . . . etc. . . . . . . . . .
Article 1 . . . . . . . . . Article 2 . . . . . . . . . etc. . . . . . . . . .
Volume 1 . . . . . . . . . Volume 2 . . . . . . . . . etc. . . . . . . . . . Figure 1 Aggregation of textual units |
|
Factor 1 Factor 2 Factor 3 (observational) (theoretical) (methodological) ─────────────────────────────────────────────────── Introduction -.69373 -.94153 .93929 Methods and Materials -.41174 -.30620 -1.40951 Results 1.48498 -.16397 .13393 Conclusion -.37950 1.41170 .33629 Table Two Factor scores for Janssens et al. 1986
|
Bernstein, R. L., C. Rossier, R. Van Driel, M. Brunner, and G. Gerisch, "Folate Deaminase and Cyclic AMP Phosphodiesterase in Dictyostelium Discoideum: Their Regulation by Extracellular Cyclic AMP and Folic Acid," Cell Differentiation (1981), 10, 79-86.
Olsen G. J., and M. L. Sogin, "Nucleotide Sequence of Dictyostelium discoideum 5.8S Ribosomal Ribonucleic Acid: Evolutionary and Secondary Structural Implications," Biochemistry (1982), 21(10), 2335-2343.
Weinert, T., P. Cappuccinelli, and G. Wiche, "Potent Microtubule Inhibitor Protein from Dictyostelium discoideum," Biochemistry (1982), 21(4), 782-789.
Rutherford, C. L., and S. S. Brown, "Purification and Properties of a Cyclic-AMP Phosphodiesterase That Is Active in Only One Cell Type during the Multicellular Development of Dictyostelium discoideum," Biochemistry (1983), 22(5), 1251-1258.
McCarroll, R., G. J. Olsen, Y. D. Stahl, C. R. Woese, and M. L. Sogin, "Nucleotide Sequence of the Dictyostelium discoideum Small-Subunit Ribosomal Ribonucleic Acid Inferred from the Gene Sequence: Evolutionary Implications", Biochemistry (1983), 22(25), 5858-5868.
Rutherford, C. L., R. L. Vaughan, M. J. Cloutier, D. K. Ferris, and D. A. Brickley, "Chromatographic Behavior of Cyclic AMP Dependent Protein Kinase and Its Subunits from Dictyostelium discoideum", Biochemistry (1984), 23(20), 4611-4617.
De Gunzburg, J., D. Part, N. Guiso, and M. Veron, "An Unusual Adenosine 3',5'-Phosphate Dependent Protein Kinase from Dictyostelium discoideum," Biochemistry (1984), 23(17), 3805-3812.
Marshak, D. R., M. Clarke, D. M. Roberts, and D. M. Watterson, "Structural and Functional Properties of Calmodulin from the Eukaryotic Microorganism Dictyostelium discoideum," Biochemistry (1984), 23(13), 2891-2899.
Takiya, S., K. Takahashi, M. Iwabuchi, and Y. Suzuki, "Structural and Functional Properties of Calmodulin from the Eukaryotic Microorganism Dictyostelium discoideum," Biochemistry (1985), 24(4), 1040-1047.
Bisson, R., G. Schiavo, and E. Papini, "Cytochrome c Oxidase from the Slime Mold Dictyostelium discoideum: Purification and Characterization," Biochemistry (1985), 24(26), 7845-7852.
Janssens, P. M. W., J. C. Arents, P. J. M. van Haastert, and R. van Driel, "Forms of the Chemotactic Adenosine 3',5'-Cyclic Phosphate Receptor in Isolated Dictyostelium discoideum Membranes and Interconversions Induced by Guanine Nucleotides," Biochemistry (1986), 25(6), 1314-1320.
Van Haastert, P. J. M., "Kinetics and Concentration Dependency of cAMP-Induced Desensitization of a Subpopulation of Surface cAMP Receptors in Dictyostelium discoideum," Biochemistry (1987), 26(23), 7518-7523.
Shiozawa, J. A., M. M. Jelenska, and B. C. Jacobson, "Topography of the Dictyostelium discoideum Plasma Membrane: Analysis of Membrane Asymmetry and Intermolecular Disulfide Bonds," Biochemistry (1987), 26(15), 4884-4892.
Kohnken, R. E., and E. A. Berger, "Affinity Labeling of the Carbohydrate Binding Site of the Lectin Discoidin I Using a Photoactivatable Radioiodinated Monosaccharide," Biochemistry (1987), 26(26), 8727-8735.
Kohnken, R. E., and E. A. Berger, "Assay and Characterization of Carbohydrate Binding by the Lectin Discoidin I Immobilized on Nitrocellulose," Biochemistry (1987), 26(13), 3949-3957.
Mutzel, R., M.-N. Simon, M.-L. Lacombe, and M. Veron, "Expression and Properties of the Regulatory Subunit of Dictyostelium cAMP-Dependent Protein Kinase Encoded by .lambda.gt11 cDNA Clones," Biochemistry (1988), 27(1), 481-486.
Klein, G., J.-B. Martin, and M. Sartre, "Methylenediphosphonate, a Metabolic Poison in Dictyostelium discoideum. 31P NMR Evidence for Accumulation of Adenosine 5'-(.beta.,.gamma.-Methylenetriphosphate) and Diadenosine 5',5'''-P1,P4-(P2,P3-Methylenetetraphosphate)," Biochemistry (1988), 27(6), 1897-1901.
Klein, G., D. A. Cotter, J.-B. Martin, M. Bof, and M. Sartre, "Germination of Dictyostelium discoideum Spores. A 31P NMR Analysis," Biochemistry (1988), 27(21), 8199-8203.
Table One
Bibliography of the sample (18 biochemistry articles on Dictyostelium Discoideum).
|
|
Theory |
Methods |
Observation
|
|
Theory |
17.6 %
|
|
|
|
Methods |
31.9 %
|
75.6 % |
|
|
Observation |
5.9 %
|
15.9 % |
28.7 % |
Table 3
Percentage significant (p # 0.01) correlations between lists of factor loadings for words in different dimensions among the 17 articles.
|
|
|

Figure 4
Path analytical model for the organization of words in sections
[1].
Using matrix algebra, a symmetrical co-word matrix can be generated from an
asymmetrical words/documents matrix P by multiplication with its transpose PT
(Engelsman & Van Raan, 1991).