Main-path analysis and path-dependent transitions
in HistCite™-based historiograms
Journal of the American Society for Information Science and Technology (forthcoming)
Diana Lucio-Arias1 & Loet Leydesdorff2
Amsterdam School of Communications Research (ASCoR), University of Amsterdam
Kloveniersburgwal 48, 1012 CX Amsterdam, The Netherlands.
1tel.: +31-20- 5253753; fax: +31-20- 525 3681; D.P.LucioArias@uva.nl
2 loet@leydesdorff.net; http://www.leydesdorff.net
With the program HistCite™ it is possible to generate and visualize the most relevant papers in a set of documents retrieved from the Science Citation Index. Historical reconstructions of scientific developments can be represented chronologically as developments in networks of citation relations extracted from scientific literature. This study aims to go beyond the historical reconstruction of scientific knowledge, enriching the output of HistCite™ with algorithms from social network analysis and information theory. Using main path analysis, it is possible to highlight the structural backbone in the development of a scientific field. The expected information value of the message can be used to indicate whether change in the distribution (of citations) has occurred to such an extent that a path-dependency is generated. This provides us with a measure of evolutionary change between subsequent documents. The “forgetting and rewriting” of historically prior events at the research front can thus be indicated. These three methods are applied to a set of documents related to fullerenes and the fullerene-like structures of nanotubes.
Introduction
Derek de Solla Price (1965) proposed using the literary model as a functional simplification of the process of scientific discovery and communication. In this model the dynamics, developments, and structure of science are operationalized in terms of networks of scientific papers (Garfield, 1979). The model was originally applied to trace scientific developments historically (Garfield et al., 1964), but was also used to study scientific specialties (Griffith et al., 1974; Small & Griffith, 1974), influences in science (Stewart, 1983), etc. Given that publishing their scientific results is one of the scientists’ main and perhaps most relevant activities, this operationalization may provide an accurate proxy for the study of scientific developments. Through the literary model, scientific developments can be associated with the accumulation of scientific accomplishments.
Citations can be considered as unidirectional links that relate later documents to earlier ones (Garfield, 1973; Small & Griffith, 1974). The historical dependency of scientific developments operates through citations and references so that citation patterns are associated with interpretation of previous results, successful papers (Small, 1978), and the intention of scientists to position their results differently from previous ones (Fujigaki 1998a). This citation culture (Wouters, 1999) can be used to understand scientific developments in terms of patterns of references emerging and reproduced in scientific literature.
Citations can be analyzed as links between authors and/or texts (Leydesdorff & Amsterdamska, 1990). Using the literary model, citation relations are considered as links among different texts holding cognitive significance. Citations made to other documents position the citing document with reference to papers in an evolving network. The position of each paper can be expected to change over time as the research front further develops and older citations become obsolete or are overwritten by newer ones (Fujigaki, 1998a and b; Garfield, 1963; Merton, 1979, at p. vii).
The citation relation that links two documents reveals two different dynamics in the process of scientific development: codification and diffusion. In the first part of this study, a citation will be considered as codification: a “citing” document makes reference to a body of knowledge that is further codified by this reference among other possible references (Leydesdorff & Wouters, 1999). In the second part, we invert the direction and citation will be considered as an “is cited by” relation. This reflects the diffusion of knowledge claims from an original document to documents published thereafter. While codification is a reflexive process taking place in the present and reconstructing the past, the diffusion of texts can only be measured by following the arrow of time in the forward direction.
This work builds on a previously published study which provided descriptive statistics and substantive analysis of documents retrieved from the ISI Web of Science with “fullerene*” (7,696 documents) or “nanotube*” ( 9,672 documents) among their title words (Lucio-Arias & Leydesdorff, 2007). Fullerenes and nanotubes were chosen as they can be considered the subjects of closely related scientific research fronts. Fullerenes were discovered as molecules in 1985; carbon nanotubes were discovered in 1991 as special compounds with fullerene-like structures. In other words, not every fullerene can be regarded as a carbon nanotube. The literatures on both topics were closely related in the early 1990s, but the respective systems of scholarly communication seem to have differentiated increasingly thereafter (Figure 1).
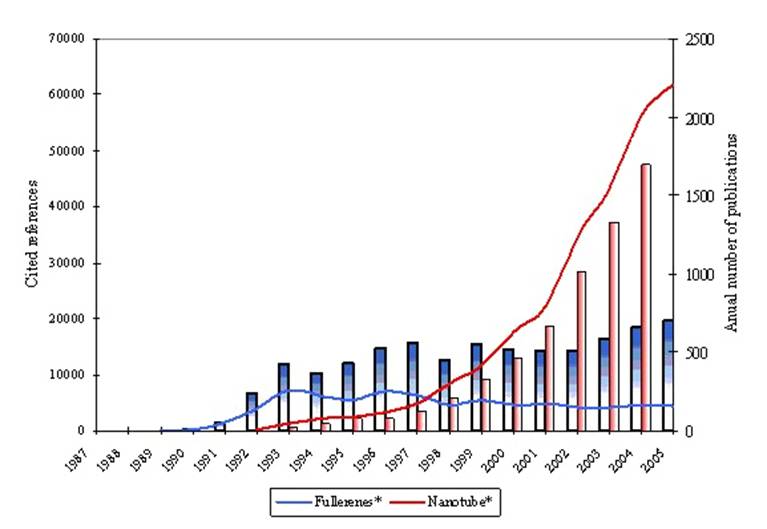
Figure 1. Documents in the SCI with “fullerene*” or “nanotube*” in their titles over time. The lines indicate the number of publications (legend on the right axis) and the bars the aggregated number of cited references per year (legend on the left axis).
In this paper, algorithmically built historiograms are used to extend the notion of two different specialties by analyzing the structures among the most frequently cited documents for each of the sets. The citing and cited relations will be analyzed in terms of codification and diffusion processes using network analysis and entropy measures. In other words, the focus of this paper is methodological: can algorithmic historiography further be extended by using quantitative measures?
For both fullerenes and nanotubes, a high aging rate of citations can be expected because these are newly emerging fields of science (Price, 1965; Chen, 2005). One can expect the short-time citation window to be reinforced by the fact that in a dynamic field of research there is a tendency to break important contributions into subsequent papers corresponding to the sequential stages of their development (Garfield et al., 1964). However, the number of documents considered (7,696 and 9,672, respectively) should be enough for a citation network that represents the historical development of research in each of these fields.
The operationalization in terms of the literary model enables us to apply algorithms in order to visualize trends associated with the development of science (Burt, 1983). Hitherto, most of the visualization tools available to map scientific literature using citation and co-citation analysis represent the state of science at specific moments of time. CiteSpace (Chen, 2005) diachronically visualizes the evolution of knowledge domains and research fronts. HistCite makes it possible to map the historical evolution of a set of papers in terms of trajectories: it generates historiograms which reflect the flow of ideas up to the moment of the last document considered. Additionally, it provides output files that can be read by software for social network analysis.
Following this section, the use of HistCite will be explained along with a demonstration of how its output can be enhanced with measures obtained from social network analysis and information theory, notably main path analysis and the study of path-dependent transitions. Results for the cases of fullerenes and nanotubes follow the methods section. Addressing the citation relations as a flow of knowledge from one paper to the next will provide us with a perspective other than the hindsight perspective of the citing papers. This diffusion mechanism as different from the codification process is discussed in the fourth section.
Methods
a) HistCite
The program HistCite creates a citation index for any defined set of documents retrieved from the ISI Web of Science, outlining the chronological network of citations among these documents (Garfield et al., 2002, 2003a, 2003b). The most significant works in a set are identified on the basis of citation frequencies, and the citation relations among these documents can be visualized. Because the tool highlights the most cited papers, their bibliographic antecedents and descendents both within and outside the set can be traced, facilitating the process of the historical reconstruction of fields of science. Garfield (2001) described this process as writing an “algorithmic historiography.” The algorithmic approach enables us to include more variety in the perspective than does a historical reconstruction based on a single narrative (Kranakis & Leydesdorff, 1989).
HistCite’s algorithmic historiograms illustrate the key works associated with the development of a field, highlighting the most frequently cited papers in each collection. If the development of the sciences is understood as a series of chronological events (Garfield et al., 1964), and the citation network is acknowledged as an emergent property of the scientists’ activities (Fujigaki, 1998a), one can consider that the network formed by relations between the most frequently cited documents represents the intellectual base from which further developments of the field unfold.
Using HistCite, the 30 most highly cited documents in each set of documents are identified. The citation relations between these documents can be exported to other programs for further analysis. For the analysis of main paths, we use Pajek, a freely available software program for the analysis and visualization of networks.[1] For the analysis of path-dependent transitions we wrote our own routines.[2] The algorithms used in this study enhance the representations from HistCite by qualifying the links with quantitative measures.
Main-path analysis associates the links (citations) to their connectivity qualities; relative entropy (Kullback & Leibler, 1951) will be used as a measure to evaluate whether the distributions of references changed between papers to such an extent that a path-dependency was created (Mei & Zhai, 2005). The three measurement outputs can then be combined into the visualization of HistCite: they show, respectively, prominence and relevance, structural connectivity, and evolutionary dynamics. While relevance is measured by considering the number of citations a given document accumulates over time, main-path analysis considers both the citations which a document receives and the documents it cites. The analysis of path-dependent transitions focuses on the (distributions of) cited references. All these measures can be associated with the positional attributes of a paper in its network of relations (Burt, 1982).
b) Main-Path Analysis
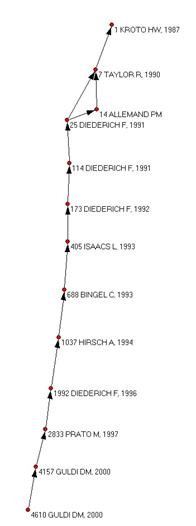
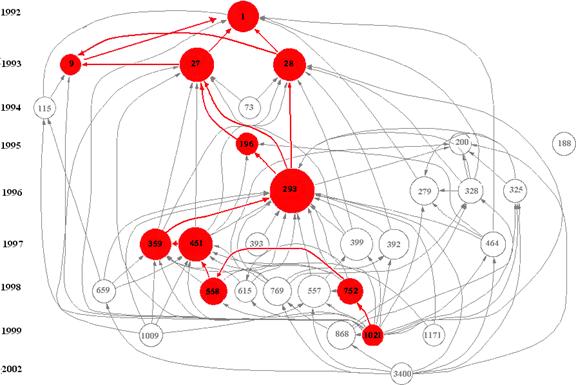
Main-path techniques examine connectivity in acyclic networks and are especially interesting when nodes are time dependent, as it selects the most representative nodes at different moments of time. In a citation network, time assigns direction to the links and each node represents a distinct event in time (Carley et al., 1993).[3] A node that links many nodes and has many nodes linking to it will probably be part of the main path. The main path will highlight those papers that build on prior papers but continue to act as an authority in reference to later works (Yin et al., 2006)
The main path is reconstructed by calculating the connectivity of the links in terms of their degree centrality and outlining the path formed by the nodes with the highest degree. In terms of a citation network, this degree measure considers the number of citations a document receives (indegree) as well as the number of cited references in the documents (outdegree). The main path is constructed by selecting those connected documents with the highest scores until an end document is reached (Batagelj, 2003). This can be either a document that is no longer cited or one that contains no further references within the set. HistCite’s output shows citations as a “cited-by” relation from the perspective of the citing documents. In the introduction, we distinguished this codification process from the diffusion process of knowledge claims in cited documents. In order to draw the main path of the most influential documents over time, it is necessary to transpose the matrix.
Citing previous literature and being cited by subsequent literature positions a paper in relation to other papers in the set (Hummon & Doreian, 1989). By constructing these positions, main-path algorithms enable us to make the structural backbone of a literature visible. When a set of documents represents a self-contained field—not significantly building on knowledge from other fields—the citation network among the key documents (the most highly cited ones) can be expected to contain at least one main path (Carley et al., 1993).
Three models to identify the most important part of a citation network can be distinguished: the Node Pair Projection Count, which accounts for the number of times each link is involved in connecting all node pairs; the Search Path Link Count, which accounts for the number of all possible search paths through the network emanating from an origin; and the Search Path Node Pair, which accounts for all connected vertex pairs along the paths (Hummon & Doreian, 1989, at pp. 50-51). Of these three methods, algorithms to estimate the latter two are included in Pajek (Batagelj, 2003).
In this study, we use the Search Path Link Count algorithm for the following reasons. The Search Path Node Pair chooses a path while forgoing citations between documents that are connected indirectly through a third document that may also be part of the path. For example, if there are citations between documents 1 and 2, documents 2 and 3, and documents 1 and 3, the main path calculated with the Search Path Node Pair will not consider the citation relation between document 1 and document 3. The Search Path Link Count is the preferred algorithm for this analysis because all citation relations are taken into account. This inclusive approach of all citation relations accords with the analysis of HistCite and path-dependent transitions.
c) Path Dependency and Critical Transitions
By applying main-path analysis as described above, documents that summarize the main stream of research in fullerenes and nanotubes can be highlighted. These documents can be expected to contain the main findings in the fields, either because they are crucial in defining the field’s cognitive history or because they represent high impact documents. In addition to connecting to other documents, however, each scientific text adds new information to the network. This information is contained in the distribution of attributes.
The expected information value I of an additional text can be expressed as a Kullback-Leibler (1951) divergence between the a prior and posteriori distributions of attributes in each of the texts. The similarity between texts can thus be measured. This relative entropy measure is formalized as follows:
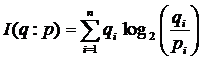 (1)
(1)
In this equation, pi = (p1, p2, …, pn) represents the a priori distribution of references (in the first text) and qi = (q1, q2, …., qn) the posterior one (that is, in the next text considered). When two is used as the basis of the logarithm, I is expressed in bits of information. I is the expected information value of the message that the a priori distribution is transformed into the a posteriori one (Kullback & Leibler, 1951; Theil, 1972; Leydesdorff, 2005). Note that I is asymmetrical in p and q.
In each text, a number of distributions of attributes can be analyzed: words, title words, cited references, citations (Leydesdorff, 1995). Because we are interested in this study in processes of codification and diffusion, we transformed the reference lists of each text into a relative frequency distribution of occurrence (f) of each reference normalized at the level of the set (fi/N). This results in size-equivalent vectors of distributions for each of the 30 most frequently cited documents that are used to measure change in the citation patterns among the documents. However, a zero in the a priori distribution (the denominator in Eq. 1) would make a non-zero value in the posteriori distribution a complete surprise, and the expected information content of the message that this happened would therefore be infinite. This would distort the analysis. For this reason, the values of the cells were increased in a unity for this analysis (Elliot, 1977; Price, 1981).
The Kullback-Leibler divergence can be used to analyze path-dependent transitions in a set of sequential events (Frenken & Leydesdorff, 2000; Leydesdorff, 1995, at p. 341). If the prediction of the distribution of references in the a posteriori text on the basis of the a priori one were perfect, the expected information content of the message that the new text arrived would be zero. The paper would be a copy of the previous one in terms of its cited references and nothing would have changed.
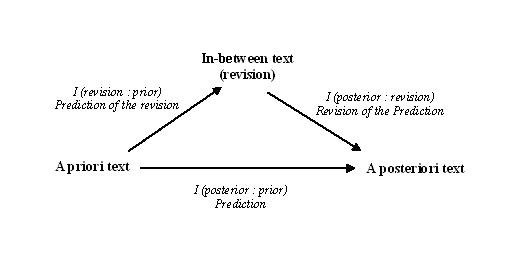
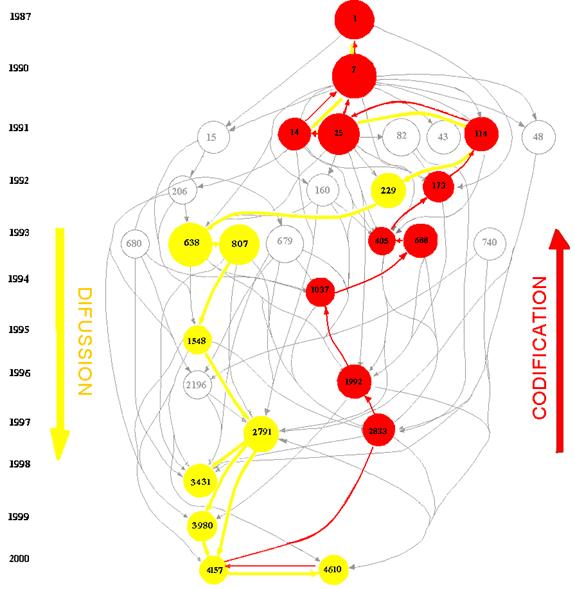
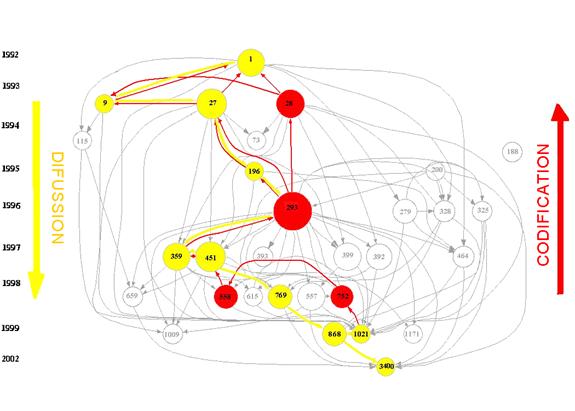
Figure 2. Prediction and possible revision of the prediction among three documents
If the prediction is imperfect, it can be improved by an in-between text (Figure 2). This improvement of the prediction of the a posteriori probability distribution (Σi qi) on the basis of an in-between probability distribution (Σi pi') compared with the original prediction (Σi pi) can be formulated as follows:
![]()
= ![]() (2)
(2)
These revisions of the prediction can occur among any three documents in a set. If I(q:p) > I(q:p') + I(p':p) the pathway in Figure 2 via the revision is a more efficient channel for the communication between sender and receiver than their direct link. Contrary to the geometry of Figure 2, the sum of the information distances via the intermediate document has become shorter than the direct information path between the sender and the receiver.
Unlike the evolutionary transitions as defined by Mei & Zhai (2005, at p. 201), the identification of these critical transitions does not require the specification of a threshold because their identification is based on the solution of an inequality. On a timeline, these critical transitions indicate documents that can be considered as path-dependencies or obligatory passing points (Callon, 1986) in the sense that the later documents (the a posteriori text and the revision) contain similarities in the distribution of their cited references which the earlier ones did not have. The communication system has changed in the dimension of the distribution(s) under study.
In the case of diffusion, a critical transition is examined from the perspective of the sender: the intermediate document in this case boosts the signal from the a priori document as an auxiliary transmitter. The history before the intermediate station is overwritten. In the case of codification, the intermediate document provides a chronologically closer alternative to define the cognitive position of the cited document. Thus, it reinforces the codification of the latter’s citation pattern in the archive because the newly added document no longer makes a difference for this position.
In general, information-theoretical measures allow for the extension to higher dimensionalities in the distribution, for example, by combining citations with title words, author names, institutional addresses, etc. The multivariate distributions remain fully decomposable (Theil, 1972). By extending the number of subscripts (pi, pij, pijk, etc.), the measurement can further be refined (Van den Besselaar & Heimeriks, 2006). In this study, however, we focus on citations in order to show how these algorithms enable us to enrich the insights obtained from using HistCite.
The analysis of path-dependent transitions provides a meaning to the links that is different from the main-path analysis obtained with social network analysis. Main-path analysis identifies a continuous path of connected and connecting nodes, while critical transitions are dispersed and represent moments in the evolution of networks where a distribution of attributes in one text is dissimilar to the distribution in a later text to the extent that the revision can be considered as a re-write of the information contained in the first text. In this case, a path-dependent transition is indicated.
Critical transitions and the consequent path-dependencies are related to complex system dynamics and indicate to which extent a system is evolving following paths determined by previous states of the system. However, an evolving system can also be expected to “forget” parts of its history from the perspective of hindsight. Because we are using a literary model and not a behavioral one, we are able to address a dimension that may be latent to the authors who are entrained in the transition.
A critical transition is formally defined in terms of Shannon-type information. Shannon-type information is dimensionless and hence without meaning. It can be provided in this study with meaning as path-dependencies given the literary model. The meaning of documents thus identified can perhaps be validated in future research by interviews with experts (e.g., Campanario, 1993). Both main-path and critical transition results are combined below with the citation diagrams provided by HistCite in order to measure connectivity and evolutionary change along with prominence for each of the links and nodes.
Results
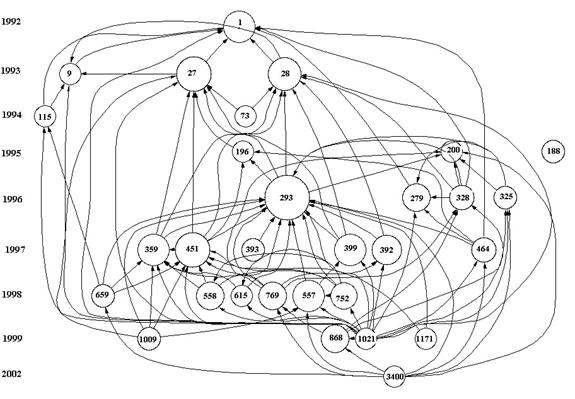
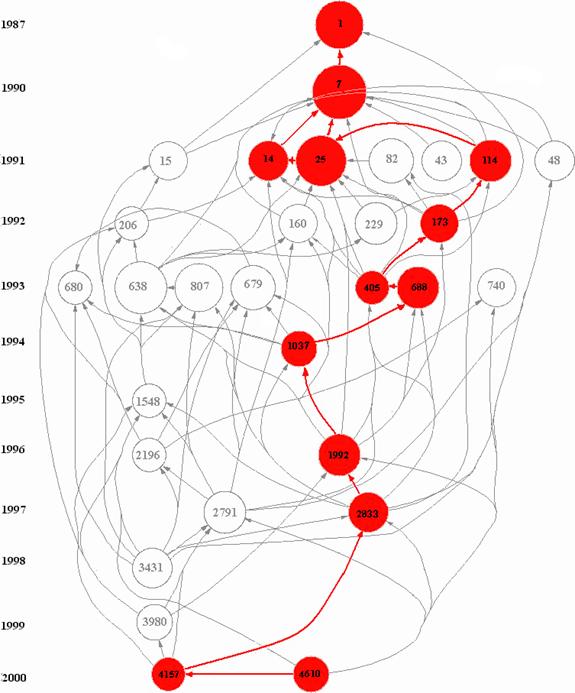
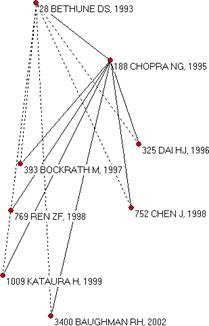
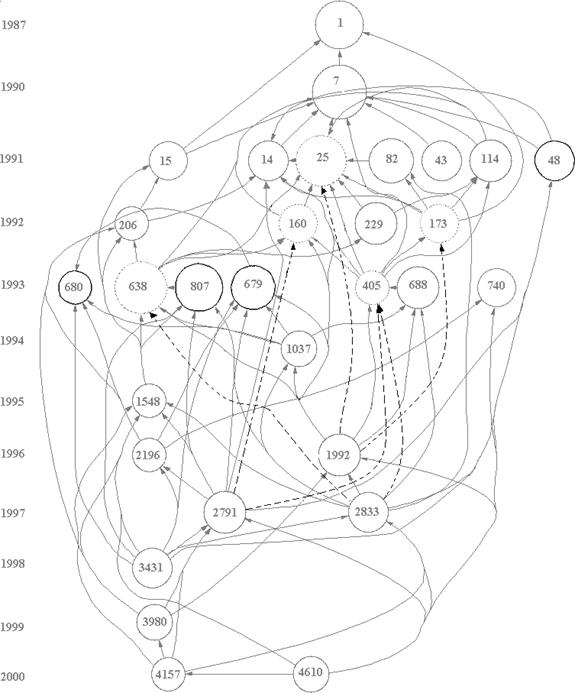
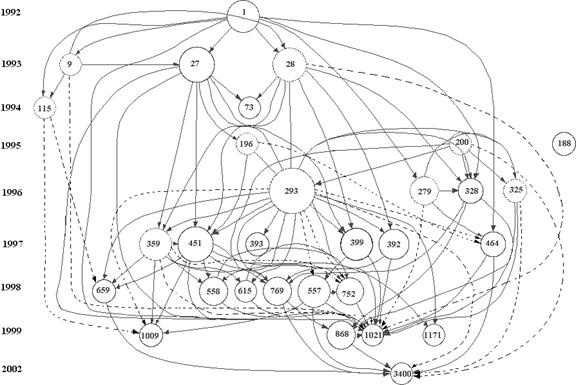
As noted, two sets of documents were retrieved from the ISI Web of Science:[4] the first, with “fullerene*” in their titles, contained 7,696 documents. The second set, based on selecting documents with “nanotube*” in their titles, contains 9,672 documents. The 30 most frequently cited documents in each of the sets and their internal relations were identified and illustrated with HistCite (Figures 3 and 4).
The analysis was limited to 30 documents for three reasons: (1) because the most often cited documents can be considered as central to the evolution of further research (Griffith et al., 1974); (2) by selecting only the most cited papers we avoid loops in the citation network formed by all the retrieved documents; and (3) the limited sets enable to enhance visually the results obtained by HistCite without overcrowding the visualizations.
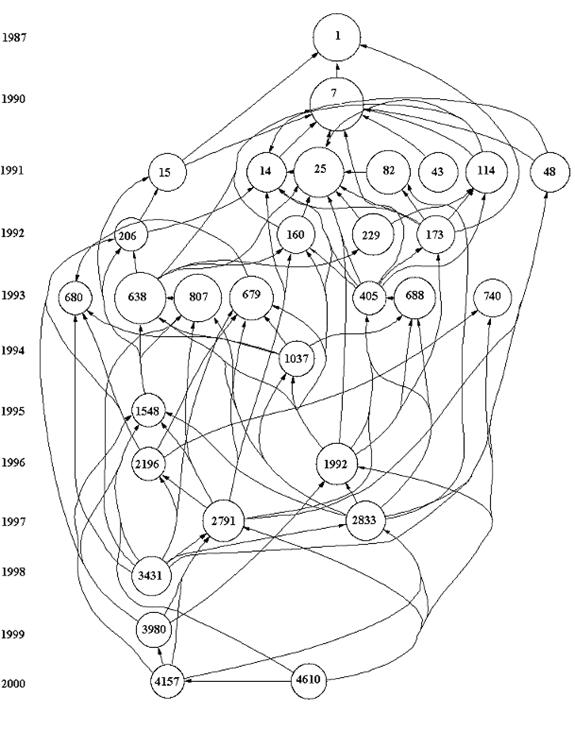 |
Figure 3. Thirty most highly-cited documents among 7,696 documents with “fullerene*” in their titles as generated by HistCite™.
|
RANK |
FIRST AUTHOR |
YEAR |
JOURNAL |
CITATIONS |
|
1 |
KROTO HW |
1987 |
NATURE |
252 |
|
7 |
TAYLOR R |
1990 |
J CHEM SOC CHEM COMM |
303 |
|
14 |
ALLEMAND PM |
1991 |
J AMER CHEM SOC |
173 |
|
15 |
HARE JP |
1991 |
CHEM PHYS LETT |
163 |
|
25 |
DIEDERICH F |
1991 |
SCIENCE |
271 |
|
43 |
HOWARD JB |
1991 |
NATURE |
166 |
|
48 |
ALLEMAND PM |
1991 |
SCIENCE |
180 |
|
82 |
CHAI Y |
1991 |
J PHYS CHEM |
212 |
|
114 |
DIEDERICH F |
1991 |
SCIENCE |
182 |
|
160 |
CREEGAN KM |
1992 |
J AMER CHEM SOC |
162 |
|
173 |
DIEDERICH F |
1992 |
ACCOUNT CHEM RES |
149 |
|
206 |
ANDERSSON T |
1992 |
J CHEM SOC CHEM COMM |
119 |
|
229 |
KIKUCHI K |
1992 |
NATURE |
195 |
|
405 |
ISAACS L |
1993 |
HELV CHIM ACTA |
127 |
|
638 |
TAYLOR R |
1993 |
NATURE |
291 |
|
679 |
FRIEDMAN SH |
1993 |
J AMER CHEM SOC |
199 |
|
680 |
SIJBESMA R |
1993 |
J AMER CHEM SOC |
124 |
|
688 |
BINGEL C |
1993 |
CHEM BER-RECL |
182 |
|
740 |
TOKUYAMA H |
1993 |
J AMER CHEM SOC |
161 |
|
807 |
MAGGINI M |
1993 |
J AMER CHEM SOC |
238 |
|
1037 |
HIRSCH A |
1994 |
ANGEW CHEM INT ED |
147 |
|
1548 |
WILLIAMS RM |
1995 |
J AMER CHEM SOC |
130 |
|
1992 |
DIEDERICH F |
1996 |
SCIENCE |
186 |
|
2196 |
JENSEN AW |
1996 |
BIOORGAN MED CHEM |
131 |
|
2791 |
IMAHORI H |
1997 |
ADVAN MATER |
188 |
|
2833 |
PRATO M |
1997 |
J MATER CHEM |
167 |
|
3431 |
PRATO M |
1998 |
ACCOUNT CHEM RES |
171 |
|
3980 |
DIEDERICH F |
1999 |
CHEM SOC REV |
141 |
|
4157 |
GULDI DM |
2000 |
CHEM COMMUN |
121 |
|
4610 |
GULDI DM |
2000 |
ACCOUNT CHEM RES |
138 |