Clustering Methodologies for Identifying Country Core Competencies, Journal of Information Science, 33(1), 21-40.
Ronald N. Kostoff
Office of Naval Research, 875 N. Randolph St, .Arlington, VA 22217 USA
Dr. J. Antonio del Río; Héctor D. Cortés
Centro de Investigación en Energía, UNAM, Temixco, Mor. México
Charles Smith
Booz-Allen Hamilton, Bethesda, MD 20852
Andrew Smith
University of Queensland, Queensland, Australia
Caroline Wagner; Loet Leydesdorff
University of Ámsterdam, Amsterdam, The Netherlands
George Karypis
University of Minnesota, Minneapolis, MN 55455
Guido Malpohl
University of Karlsruhe, Postfach 6980, 76128 Karlsruhe, Germany
Rene Tshiteya
DDL-OMNI Engineering, LLC, 8260 Greensboro Drive, Suite 600, McLean, VA 22102
Correspondence to: Dr. Ronald N. Kostoff, Office of Naval Research, 875 N. Randolph St., Arlington, VA 22217; kostofr@onr.navy.mil
Abstract
The technical structure of the Mexican science and technology literature was determined. A representative database of technical articles was extracted from the Science Citation Index for the year 2002, with each article containing at least one author with a Mexican address. Many different manual and statistical clustering methods were used to identify the structure of the technical literature (especially the science and technology core competencies), and to evaluate the strengths and weaknesses of each technique. Each method is summarized, and its results presented.
 Keywords: Mexico;
Science and Technology; Bibliometrics; Computational Linguistics; Core
Competencies; Research Evaluation; Factor Analysis; Concept Clustering;
Document Clustering; Data Compression; Network Analysis; Leximancer; CLUTO;
Greedy String Tiling
Keywords: Mexico;
Science and Technology; Bibliometrics; Computational Linguistics; Core
Competencies; Research Evaluation; Factor Analysis; Concept Clustering;
Document Clustering; Data Compression; Network Analysis; Leximancer; CLUTO;
Greedy String Tiling
1. Background and Research Objectives
1.1. Country Technology Assessments
National science and technology (S&T) core competencies represent a country’s strategic capabilities in S&T. Knowledge of country core competencies is important for myriad reasons:
1. Priority technical areas for joint commercial or military ventures
2. Assessment of a country’s military potential
3. Knowledge of emerging areas to avoid commercial or military surprise
Obtaining such global technical awareness, especially from the literature, is difficult for multiple reasons:
1. Much science and technology performed is not documented
2. Much documented science and technology is not widely available
3. Much available documented science and technology is expensive and difficult to acquire
4. Few credible techniques exist for extracting useful information from large amounts of science and technology documentation [1]
Most credible country technology assessments are based on a combination of personal visitations to the country of interest, supplemented by copious reading of technology reports from that country. Such processes tend to be laborious, slow, expensive, and accompanied by large gaps in the knowledge available. The more credible and complete evaluation processes will focus on selected technologies from a particular country, and provide in-depth analysis.
For the past half century, driven mainly by the Cold War, a large number of country technology assessments were performed [2-14]. The last two decades have seen an expansion in focus to technologies of major economic competitors. Over the past two decades, some of the most credible of these country technology assessments have come from two organizations: World Technology Evaluation Center (WTEC-Loyola University) and Foreign Applied Sciences Assessment Center (FASAC-SAIC). In conducting their studies, both of these organizations would gather topical literature from the country of interest, assemble teams of experts in the topical area, have the teams review the literature as well as conduct site visitations, and have the teams brief their findings and write a final report. The studies performed by these groups remain seminal approaches to country technology assessments.
1.2. Text Mining Technology Assessments
The first author’s group has been developing text mining approaches to extract useful information from the global science and technology literature for the past decade [15-26]. These studies have typically focused on a technical discipline, and have examined global S&T efforts in this discipline. It is believed that such approaches, with slight modification, could be adapted to identifying the core S&T competencies in selected countries or regions, including estimation of the relative levels of effort in each of the core technology areas. It is also believed that coupling of the text mining approach with WTEC and FASAC approaches would amplify the strengths of each approach and reduce the limitations. The text mining component would be performed initially to identify:
· Key core competencies and technology thrusts in the country of interest
· Key interdisciplinary thrusts
· Approximate levels of efforts in technology-specific competency areas and in interdisciplinary areas
· Highly productive researchers
· Highly productive Centers of Excellence, including those not well known
· Highly cited researchers
Once the key technologies, researchers, and Centers of Excellence had been identified, then site visitation strategies could be developed. The second phase of the effort would be the actual site visitations. A key step in this hybrid process would be demonstration of the ability of text mining to identify the targets of interest with reasonable precision in a timely manner at an acceptable cost. These three driving parameters (performance, time, cost) could be traded-off against each other to provide a balance acceptable and tailored to a variety of potential customers.
1.3. Research Objectives
Evaluate approaches for identifying the technology core competencies of the Mexican research literature, and for assessing levels of effort/ emphasis in these core competencies. Include both manual and statistical approaches. Identify unique capabilities of each approach. Focus on clustering approaches whose categories will be determined by the data and algorithms, rather than using pre-determined categories. Include network-based approaches as well, especially for identifying the relationships among categories. Compare results from the different core competency identification approaches.
2. Overview of Approaches and Databases Used
2.1. Overview
Two major types of information are required for a country S&T core competency assessment. One is technical infrastructure, which encompasses the prolific performers, journals that contain many of the papers, the prolific institutions, and the most cited papers/ authors/ journals. The other is technology thrusts, and the relationship among the thrusts. This study focused on obtaining multiple approaches for identifying the S&T thrusts and their relationships.
Section 2.2 describes the database used for the taxonomy analyses. Based on the sampled set of 4529 retrieved papers representing Mexico’s total research, two types of taxonomies are presented, manual and statistical. The manual taxonomies require mainly hand-classification of Abstracts, journals, and keywords into categories, whereas the statistical approaches use more computer-based pre-classification. In both approaches, strong human input is required for final categorization. Section 3 presents the manual taxonomy approaches and results, sections 4-6 present the statistical taxonomy approaches and results, and section 7 presents taxonomy comparisons.
There are five manual taxonomy results presented (section 3), and three major classes of statistical taxonomy approaches presented (concept clustering (section 4), document clustering (section 5), network mapping (section 6)). Concept clustering is the grouping of words or phrases based on their co-occurrence in the same text unit. In the present paper, concept clustering techniques include factor matrix-based clustering and multi-link hierarchical aggregation clustering.
Document clustering is the grouping of similar documents into thematic categories. Different approaches exist [29-36]. In document clustering, documents are clustered based on their overall text similarity. In the present paper, document clustering techniques include Greedy String Tiling (section 5.1), entropy-based data compression (section 5.2), partitional (section 5.3), journal (section 5.4), and latent semantic (section 5.5).
Network Mapping presents analysis of Mexico’s technology capabilities using network analysis of word co-occurrence to reveal patterns within the data. These patterns can provide information that would not be evident from a visual examination of the data.
The reader interested in detailed results on any of the techniques mentioned above should obtain reference [27].
2.2. Databases and Information Retrieval Approach
For the present study, the Science Citation Index database was used as the record source. At the time the final data was extracted for the present paper (Fall 2002), the version of the SCI used accessed about 5600 journals (mainly in physical, environmental, engineering, and life sciences basic research). The retrieved database used for analysis consisted of selected journal records (including the fields of authors, titles, journals, author addresses, author keywords, abstract narratives, and references cited for each paper) obtained by searching the Web version of the SCI for articles that contained at least one author with a Mexico address.
3. Manual Taxonomies
Five manual categorization techniques were compared: Article Titles, Journal Titles, Keywords, Full Abstracts, Journals. Table 1 compares the different manual categorizations of articles into technical disciplines. If manual categorization of the Full Abstracts is taken as the benchmark, then manual characterization of the Article Titles is the best approximation, and Keyword and Journal Title counts are poorer approximations.
Table 1. Comparison of Manual Categorization Techniques
|
Manual Categorization Comparisons |
Article Titles |
Journal Titles |
Keywords |
Full Abstracts |
Journals |
|
Physics |
29.90% |
37.50% |
26.00% |
23.10% |
20.40% |
|
Biological and Medical Sciences |
33.20% |
31% |
57.60% |
34.70% |
39.90% |
|
Chemistry |
16.50% |
11.90% |
10.10% |
12.90% |
10.30% |
|
Other Topics |
7.10% |
6.40% |
2.90% |
10.50% |
11.80% |
|
Agriculture |
4.70% |
3.60% |
1.80% |
4.90% |
3.70% |
|
Mathematical and Computer Science |
3.60% |
3.60% |
0.40% |
6.30% |
5.30% |
|
Earth Sciences and Oceanography |
2.50% |
2.60% |
0.60% |
5.10% |
4.70% |
|
Material Science |
2.50% |
3.50% |
0.60% |
2.40% |
3.80% |
4. Concept Clustering
Two statistically-based concept clustering methods were used to develop taxonomies, factor matrix clustering and multi-link clustering. Both offer different perspectives on taxonomy category structure from the document clustering approach described later. None of the clustering approaches included here is inherently superior.
In this section, a synergistic combination of factor matrix and multi-link clustering is described that offers substantial improvement in the quality of the resultant clusters. Once the appropriate factor matrix has been generated, the factor matrix can then be used as a filter to identify the significant technical words for further analysis. Specifically, the factor matrix can complement a basic trivial word list (e.g., a list containing words that are trivial in almost all contexts, such as ‘a’, ‘the’, ‘of’, ‘and’, ‘or’, etc) to select context-dependent high technical content words for input to a clustering algorithm. The factor matrix pre-filtering will improve the cohesiveness of clustering by eliminating those words that are trivial words operationally in the application context [28-29].
The remainder of this section presents the multi-link clustering only. See reference 27 for factor matrix details.
4.1. Multi-Link Hierarchical Word Clustering
4.1.1 Multi-Link Clustering Approach
A symmetrical co-occurrence matrix of the highest frequency high technical content words/ phrases was generated. The matrix elements were normalized using the Equivalence Index (Eij=Cij^2/Ci*Cj, where Ci is the total occurrence frequency of the ith word/ phrase, and Cj is the total occurrence frequency of the jth word/ phrase, for the matrix element ij), and a multi-link clustering analysis was performed using the WINSTAT statistical package. The Complete Linkage hierarchical aggregation method was used. A detailed description of the final word dendrogram (a hierarchical tree-like structure), and the aggregation of its branches into a taxonomy of categories, are shown in reference [27]. A summary description now follows.
4.1.2 Multi-Link Word Clustering Results
Complete Link clustering was used. The top level clusters form a flat set. Some of the clusters have a distinct hierarchical structure into sub-clusters, where a technology area can be divided into its specific sub-technologies.
The 249 words in the dendrogram are grouped into top level clusters. At this level, five broad topics (Categories) can be discerned from visual inspection of the types of words in each cluster. These include biology, medicine, physics, chemistry, and environment. Each of these highest level clusters is then divided into smaller clusters by the technical experts, who evaluate the mix of words in each smaller cluster, and then assign a theme to each cluster.
Category 1 - Biology
There are four main groupings: membrane biology/ cell-cell recognition; microbial molecular biology/ gene expression; recombinant DNA biology; plant population genetics.
Category 2 - Medicine
There are five main groupings: cardiopulmonary; reproductive; liver damage; immunology; chronic disease treatment.
Category 3 - Physics
There are four main groupings: quantum and dynamical systems; accelerator physics; solid-state; astrophysics.
Category 4 - Chemistry
There are three main groupings: polymers; molecular characterization; thin films.
Category 5 - Environment
There are four main groupings: forest and agriculture; oceanography and geophysics; heavy metals in sediments; fish growth.
These thematic areas coincide with the major thematic areas listed in Table 1, especially those determined by manual categorization of the full Abstracts. In Table 1, Agriculture and Earth Sciences and Oceanography were listed as separate themes, whereas the present taxonomy lists them under Environment.
5. Document Clustering
Document clustering is the grouping of similar documents into thematic categories. Different approaches exist [30-37]. Five approaches were examined in this paper: Greedy String Tiling, Entropy-based Data Compression, Partitional Clustering, Automatic Journal Categorization, and Latent Semantic Clustering.
5.1. Greedy String Tiling
5.1.1 Greedy String Tiling Approach
The approach presented in this section is based on a Greedy String Tiling (GST) text matching algorithm [38-39]. Basically, GST clustering forms groups of documents based on the cumulative sum of shared strings of words. Each group is termed a cluster, and the number of records in each cluster, and the highest frequency technical keywords in each cluster, are two outputs central to this analysis.
5.1.2 Greedy String Tiling Results
A five percent similarity threshold produced a total of 1072 clusters. Ninety-three percent of the clusters contained eight Abstracts or less. The 64 largest clusters, (containing 804 Abstracts) were extracted.
The taxonomy defined by the word clustering algorithms was used to categorize the 64 clusters generated by the Greedy String Tiling approach. Each cluster was assigned to the most appropriate category in the taxonomy defined by the WINSTAT-generated dendrogram of the last section, based on the theme suggested by the highest frequency technical keywords. The number of records in each taxonomy category from all the clusters in the category was calculated, and is shown in Table 2.
Table 2. Assignment of GST Clusters to Categories
|
Cluster Number |
Biology |
Medicine |
Physics |
Chemistry |
Environment |
|
1 |
|
|
75 |
|
|
|
2 |
|
|
|
|
26 |
|
3 |
|
25 |
|
|
|
|
4 |
|
|
|
19 |
|
|
5 |
|
|
|
17 |
|
|
6 |
|
|
|
17 |
|
|
7 |
|
|
16 |
|
|
|
8 |
|
|
16 |
|
|
|
9 |
|
15 |
|
|
|
|
10 |
|
15 |
|
|
|
|
11 |
|
15 |
|
|
|
|
12 |
|
|
13 |
|
|
|
13 |
|
13 |
|
|
|
|
14 |
13 |
|
|
|
|
|
15 |
|
|
|
|
13 |
|
16 |
|
|
12 |
|
|
|
17 |
|
|
|
|
12 |
|
18 |
|
|
12 |
|
|
|
19 |
|
|
|
|
12 |
|
20 |
|
12 |
|
|
|
|
21 |
|
|
|
12 |
|
|
22 |
|
11 |
|
|
|
|
23 |
|
|
|
11 |
|
|
24 |
|
|
11 |
|
|
|
25 |
|
|
11 |
|
|
|
26 |
|
|
11 |
|
|
|
27 |
|
11 |
|
|
|
|
28 |
|
|
|
11 |
|
|
29 |
|
|
|
11 |
|
|
30 |
|
11 |
|
|
|
|
31 |
|
|
|
|
11 |
|
32 |
|
|
|
11 |
|
|
33 |
|
|
10 |
|
|
|
34 |
|
10 |
|
|
|
|
35 |
|
|
10 |
|
|
|
36 |
10 |
|
|
|
|
|
37 |
|
|
|
10 |
|
|
38 |
|
|
|
|
10 |
|
39 |
|
|
|
10 |
|
|
40 |
|
10 |
|
|
|
|
41 |
|
|
|
10 |
|
|
42 |
|
|
10 |
|
|
|
43 |
|
|
10 |
|
|
|
44 |
|
|
10 |
|
|
|
45 |
|
10 |
|
|
|
|
46 |
|
|
|
10 |
|
|
47 |
|
|
10 |
|
|
|
48 |
9 |
|
|
|
|
|
49 |
|
|
9 |
|
|
|
50 |
|
|
9 |
|
|
|
51 |
9 |
|
|
|
|
|
52 |
9 |
|
|
|
|
|
53 |
9 |
|
|
|
|
|
54 |
|
|
9 |
|
|
|
55 |
|
|
|
9 |
|
|
56 |
|
9 |
|
|
|
|
57 |
9 |
|
|
|
|
|
58 |
|
|
|
9 |
|
|
59 |
|
|
|
9 |
|
|
60 |
|
|
|
|
9 |
|
61 |
|
|
|
|
9 |
|
62 |
|
|
|
9 |
|
|
63 |
|
|
|
|
9 |
|
64 |
|
9 |
|
|
|
|
SUM |
68 |
176 |
264 |
185 |
111 |
|
SUM (NORM) |
0.08457711 |
0.21890547 |
0.32835821 |
0.2300995 |
0.1380597 |
Compared to the full Abstracts results of Table 1, the present GST categorization provides reasonable agreement in Biology and Medicine (30 vs 34%), modest agreement in Physics (23 vs 33%), and poor agreement in Chemistry (13 vs 23%).
5.2. Data Compression Clustering
5.2.1 Data Compression Clustering Approach
The compression algorithm approach [40] of this section assumes that the entropy of a string can be measured when this string is zipped (compressed). The main idea is that when one compresses two strings sequentially, the compression rate will increase if the second string is similar to the first one, and then the zipped string will have less disorder (entropy) than the previous two strings. The entropy is defined as
A) Entropy = (Length(zip(A+b))-Length(zip(A)) - Length(zip(b+b))+Length(zip(b)) )/ Length(b).
Where A is the patron text, b is the abstract to be analyzed, and zip indicates the zipped function. The fundamental objective is to automate the classification of records into pre-defined categories, such as the DTIC themes. The complete abstract of each record is then compared against the patron text for each pre-determined DTIC theme, and then each record is assigned to an area that provides the best match.
Nineteen patron texts or lexicons for nineteen DTIC themes are defined. With these nineteen DTIC theme dictionaries, the 4529 abstracts are compressed. Then, using the best compression rate, the corresponding first level categorization theme for each abstract is selected.
Two other variants of the Entropy formula are used:
B)Entropy = (Length(zipL(A+b))-Length(zipL(A))-Length(zipL(b+b))+Length(zipL(b)) )/Length(b).
where zipL indicates a zipping process with the lexicon as parameter. This variant allows shorter calculation time.
C) Entropy = (Length(zipL(L+b))-Length(zipL(L))-Length(zipL(b+b))+Length(zipL(b)) )/ Length(b).
where the difference is that the Lexicon has been used as a patron text. The computational time is reduced on the order of 6 to 3 hours. relative to the A to C Entropy measurement.
5.2.2 Data Compression Clustering Results
Here, it is important to note that with this method it is possible to analyze all Abstracts.
The results for automated classification with relative entropy defined by A), B) C) are given in Tables 3A-C.
Table 3A. Automated Classification A Formula
|
Physics |
23% |
|
Biological and Medical sciences |
32% |
|
Chemistry |
8% |
|
Agriculture |
8% |
|
Mathematical and Computer sciences |
9% |
|
Earth sciences and Oceanography |
8% |
|
Material sciences |
12% |
Table 3B. Automated Classification B Formula
|
Physics |
16% |
|
Biological and Medical sciences |
37% |
|
Chemistry |
6% |
|
Agriculture |
7% |
|
Mathematical and Computer sciences |
11% |
|
Earth sciences and Oceanography |
4% |
|
Material sciences |
19% |
Table 3C. Automated Classification C Formula
|
Physics |
16% |
|
Biological and Medical sciences |
38% |
|
Chemistry |
6% |
|
Agriculture |
7% |
|
Mathematical and Computer sciences |
11% |
|
Earth sciences and Oceanography |
4% |
|
Material sciences |
18% |
Although there are some differences between these approaches and the manual characterization, all these results are statistically equivalent to the manual using the Chi-squared statistical test.
5.3. Partitional Clustering
5.3.1 Partitional Clustering Approach
The approach presented in this section is based on a partitional clustering algorithm [41] contained within a software package named CLUTO. Most of CLUTO’s clustering algorithms treat the clustering problem as an optimization process that seeks to maximize or minimize a particular clustering criterion function defined either globally or locally over the entire clustering solution space. CLUTO uses a randomized incremental optimization algorithm that is greedy in nature, and has low computational requirements.
5.3.2 Partitional Clustering Results
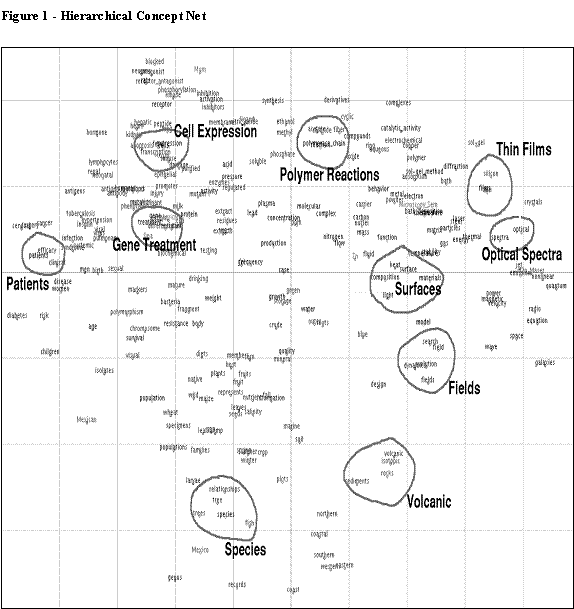
In partitional clustering, the number of clusters desired is input, and all documents in the database are included in those clusters. The 64 clusters were aggregated into a hierarchical taxonomy using a hierarchical tree generated by the CLUTO software. The taxonomy is shown in Figure 1. The categories in the taxonomy levels, and the number of documents in each category, are described as follows:
On Figure 1, the columns represent the taxonomy levels. There are six levels depicted in this taxonomy. The highest level (two categories) is the first column, and the lowest level shown (approximately 64 levels) is the last column. The numbers in parentheses represent the number of records assigned to the category.
The first level has two categories: Biomedical and Ecological (2094) and Engineering and Physical Science (2435). Percentage-wise, this is a split of 46/54%. In Table 2 (the manual assignment of GST clusters to categories defined by the word clustering approach), combining the Biology, Medicine, and Environment categories is equivalent to the Biomedical and Ecological category in Figure 1, and combining the Physics and Chemistry categories is equivalent to the Engineering and Physical Science category in Figure 1. In Table 2, the category split of 44/56% compares very favorably with the 46/54% split of Figure 1. In Table 1, the category split of 45/ 55% for the manual clustering of the full Abstracts compares favorably as well.
In Figure 1, the second taxonomy level is generated by sub-dividing each first level category by two. Biomedical and Ecological divides into Biomedical (1267) and Ecology (827), while Engineering and Physical Science divides into Materials and Films (893) and Mathematical, Physics, and Astrophysics Modeling (1542).
Again, comparing Figure 1 with Table 2, Biomedical (from Figure 1) is roughly equivalent to the combination of Biology and Medicine (from Table 2), and Ecology (from Figure 1) is roughly equivalent to Environment (from Table 2). The term ‘roughly’ is used because sometimes allocation to Biology vs Medicine is not overly clear, or assignment to Biology vs Environment is not overly clear. The Biomedical/ Ecology ratio from Figure 1 (1.53) compares only modestly well with the (Biology & Medicine)/Environment ratio from Table 2 (2.2). The definitional uncertainties are reflected in quantitative differences. Inspection of the GST clusters vs their partitional clustering counterparts shows that these quantitative differences represent manual assignment of clusters to categories vs computer assignment of clusters to categories, more than any intrinsic cluster differences.
Further, Materials and Films (from Figure 1) is roughly equal to Chemistry (from Table 2), and Mathematical, Physics, and Astrophysics (from Figure 1) is roughly equal to Physics (from Table 2). The term ‘roughly’ is used here because sometimes the allocation to Chemistry vs Physics is not overly clear, especially for materials projects, where the physics of materials and the chemistry of materials are sometimes indistinguishable. The (Materials and Films)/ (Mathematical, Physics, and Astrophysics) ratio from Figure 1 (.58) compares reasonably well with the Chemistry/ Physics ratio from Table 2 (.70). Also, the (Materials and Films)/ (Mathematical, Physics and Astrophysics) ratio from Figure 1 (.58) compares well with the (Chemistry and Materials Sciences)/ (Physics and Mathematical and Computer Science) ratio of full Abstracts from Table 1 (.52).